


PDF 阅读不是问题,关联才是。
电脑的桌面上散落着十几个 PDF 文件,很多都读过,有些做了高亮,经常复制到不同的笔记 App 里面,寻找关键引文的出处,还要打开各个文件,在不同的窗口间来回切换 ……
我们且不说 学术论文的研究者,那些都是重度的文献使用者。 哪怕 一个普通的调研,也可能涉及多份材料,还有,一个博主或内容创作者也可能会使用很多素材,然后基于此创作自己的内容。
多文件、多文献、多素材的聚合管理一直是难题,这已经不是什么PDF 阅读器 或 高亮标注工具 的领域了,更像是如何运用和整理铺天的信息。而且,这些信息还是碎片化的,如果是常见的 PDF 文件,我们的文献就会散落在不同的文件夹里,而不同资料之间的片段的深层联系,只存在于我们自己的大脑里,这无疑是巨大的脑力负担。 我个人认为,这也是创作者必经的道路,大脑肯定是要过一遍的,但也应该有更具效率的承载方式。
和 一般的逐个文件打开的 PDF 阅读器不同,今天要介绍的这款 App,选择一个不同的角度,把阅读器直接内置到我们思考和创作的工作空间里。 这样一来,就可以避免 PDF杂乱 和引用 「碎片化」的问题。在同一个主题的工作空间里, 一切都是关联的,甚至一目了然的。
这就是我今天要介绍的 Kosmik PDF 阅读器,希望可以重构不少人的工作流,特别是「视觉笔记」爱好者,也许会感到欣喜!
Kosmik PDF Reader 登场
这款工具早些年我就注意到了,Kosmik 是一个画布笔记工具, 除了 PDF、网页;其他素材也是可以把玩的。 今天我们还是说 PDF。 PDF 是一种常用的文献格式, 除了传统的PDF 阅读器, Heptabase, MarginNote, LqiuidText 之类 也是很有意思的批注或笔记工具,甚至 LogSeq 也可以在 PDF + 大纲笔记上碰出一些火花。 Kosmik 则选择了 画布笔记+ PDF。
在画布上与信息互动
Kosmik 最与众不同的地方在于,当我们打开一个 PDF 时,它不会霸占整个屏幕,而是可以在画布或侧边栏中安静地展开。主工作区还是那块无限画布。画布会完整地呈现在用户面前。这意味着 不再需要在「阅读」和「笔记」之间切换,可以同时进行。
缩放、翻页、目录跳转功能我就不赘述了,这些都是阅读工具的标配。至于,连线、插入图形元素之类,也不多说了,这些是画布工具的标配。 Kosmik 常规的功能几乎都有。
我们来聊聊它真正改变游戏规则的几个特点。
- 文本提取:在侧边栏的 PDF 中,用光标选中任意一段文字,直接将它拖拽到画布上。这段文字会立刻变成一个独立的文本卡片,我们可以随意编辑排版。(可以参考 Heptabase,Heptabase 也很强大,不单单是画布,我们下次单独讲)
- 图像与区域提取:看到一张图表或一个图片,使用内置的「选择」工具,圈出想要保存的任何区域,然后拖到画布上,它也会变成一张独立的卡片。
- 溯源:最关键的是,所有被提取出来的内容,都会自动附带一个「来源链接」。只需轻轻一点这个链接,侧边栏的 PDF 就会立刻跳转回内容的原始页面。
想象一下这个工作流:当我们在写一篇论文,从 20 份文献中提取了关键论点。几个月后,需要核对其中一句引文的上下文。不再需要去回忆这句话来自哪篇论文的第几页,只需点击画布上那张卡片,源文件和具体位置就会瞬间呈现在你眼前。这种心流不被打断的体验,对于深度研究者来说价值非凡。

用视觉关系取代文件夹层级
传统的文件管理方式是线性的或树状层级的(文件夹/子文件夹)。但我们大脑其实除了结构化的理解、也有空间化理解的加成。有可能是左右半脑分工,我倒不是说一定是「结构化」更好还是「空间化」更好,只是有人更擅长空间化思维,Kosmik 的无限画布恰好迎合了这一点。
我们可以把相关的论文、提取出的卡片、想法和笔记都放在同一个视觉空间里。用连线将它们串联起来,构建出一张属于你自己的「文献综述地图」或「灵感情绪板」。这种空间布局本身就在帮助你思考和发现不同信息之间的潜在联系,这是传统列表式或文件夹式管理无法给予的。
不过话说回来,对于强结构化的大脑来说,这种方式就不太讨喜,尽管如此,空间画布也是管理资料关系的有力补充。
超越 PDF
除了 PDF, 其实用来阅读学习 文本、图片、网页都是可以的,甚至 拿一段油管视频也可以。 总之 Kosmik 像是一个把材料扔到画布上阅读切片理解的工具。对于网页素材, Ksomik 提供了 一个 Clipper 插件用于收集网页剪贴。
不过要注意的是,像网页或视频这类素材必须通过客户端才能打开,估计是因为浏览器处于安全因素考虑,不允许嵌套访问部分其它网页造成的。也就是说,网页版的 Kosmik 功能相对会弱一点,桌面客户端会更强大。
Web 和 AI 搜索
除了上传 PDF 或其它文件素材, Kosmik 也可以直接在系统内搜索网络,或向AI提问;而返回结果会以一堆资料卡片的形式呈现在画布上,我估计会逼死一些强迫症患者。

我个人觉得这样做的意义很有限。市面上,成熟的 AI 工具和搜索引擎很多, 按我「工具链」的思维方式,工具各自分工,做好自己最擅长的事情即可。
Kosmik 就是在画布上存放和管理信息的地方,像是一个砧板,不要硬把食品生鲜超市整条供应链都集成到一块砧板上。
一些遗憾
按官方说法,Kosmik 的搜索功能也是 画布级别的。当输入一个关键词,它应该会同时检索画布上所有 PDF 文件的全文内容。但是实际上,截止目前,火箭君发现,这个全局搜索的能力是很有限的。 某些可以匹配,某些不能,没有特别规律,和语言或OCR 似乎关系也不大。
Kosmik 引入了 AI tagging(下图) ,对于素材进行自动分类,但是似乎也不是很理想,AI 标签这本身就是一个比较难的课题。

而且,作为一个推崇「本地优先」和「数据主权」的博主,我注意到 Kosmik 目前主要依赖云端同步。虽然这带来了无缝的跨平台体验(支持 macOS, Windows 和 Web),但我仍然期待它未来能提供一个更强大的完全离线模式,或者允许用户选择自己的存储后端,这会让它在注重隐私和数据安全的用户群体中更具吸引力。 不过显然这样一来,受众就更小了,盈利机会也变小了。
最后
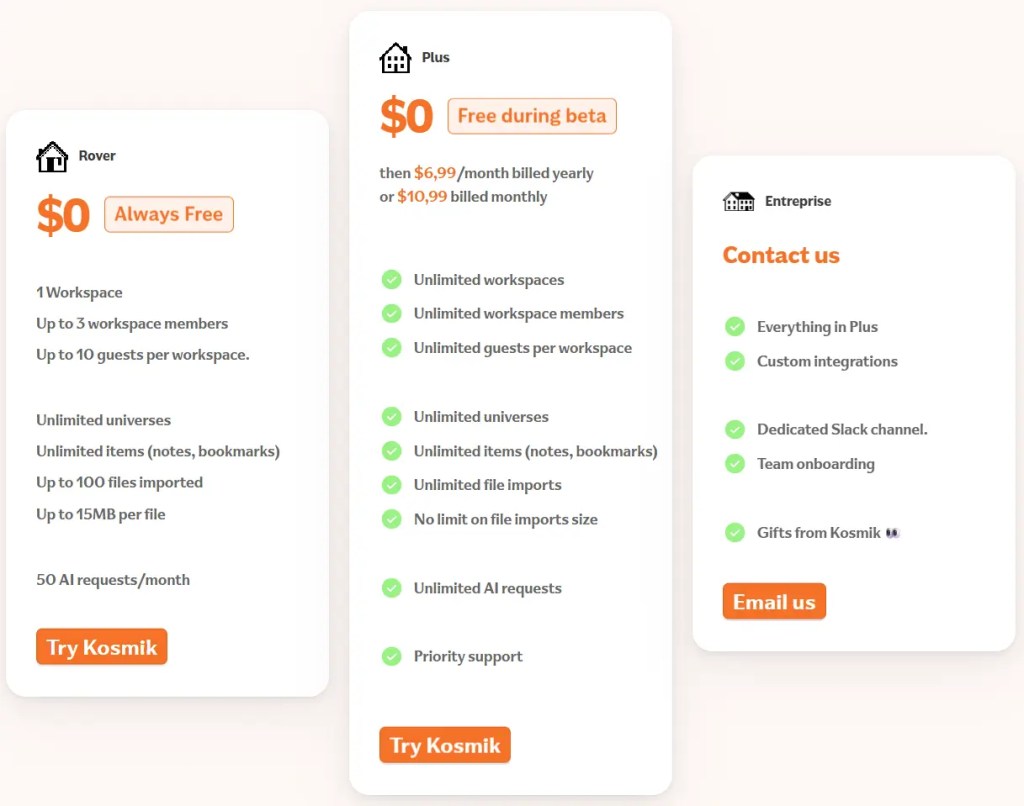
Kosmik 提供了一个免费的 Rover 计划,这对于大多数轻度用户和想要尝鲜的人来说非常友好。但它有一些限制,比如单个文件最大 15MB,总文件数量上限为 100 个。对于需要处理大量高清扫描文献或大型报告的用户,可能需要考虑他们的 Plus 付费计划,该计划解除了文件大小和数量的限制。
我早几年调研过很多画布类的工具,有些停止运营了,有的转型流量捞钱。但 Kosmik 一直都在,虽然不知道能坚持多久。
我个人希望,Kosmik 能接下火种传承下去,在未来能看到这类「可视化」阅读器发扬光大,成为一个研究学习工具的分支。不过挑战也很大,主要是 「可视化」更容易朝着肤浅炫技的方向前进,而很难朝深入研究的领域进发,这也是之前一些类似失败例子给我的感想。
