

我之前介绍过我一些表现非常出色的 AI 语音输入法。 我当时提到是:性能出色,但隐私还要谨慎留意。 现在有越来越多的证据表明,一些 AI 语音输入法(确切的说,已经超出了输入法的权限),正在看我们的屏幕,从而获得更准确的「上下文」,提供更好的语音识别和内容生成。
通过给屏幕截图,分析上面出现过的内容,然后再结合我们的语音,AI 显然可以给出更准确的识别结果。 比方说,我正在写一篇 关于 笔记工具 的 文章, 当 AI 输入法看到了我屏幕上的文章时,再听到我说 Notion,Obsidian 时 会给出更好的识别, 这是单纯语音识别难以做到的。
有各家 AI工具 厂商已经明示或暗示了用户:
- 比如 ChatGPT 桌面端明显在强调「chat about … anything on your screen」,并提供截图工具让我们把当前屏幕内容交给它分析。
- Microsoft 的 Copilot Vision 也走同一路线,官方描述就是「让 Vision 看见屏幕上打开的浏览器窗口或 App」,然后基于画面给我们步骤式指导。
- 而在「AI 语音输入/听写」圈子里,Superwhisper 这类工具把它叫做 Context Awareness,明确列出多种上下文来源(应用的情况/选中的文本/剪贴板等)。
- Wispr Flow 甚至直接写在页面上:会用「limited screen context」来保证在消息和邮件里把不常见的人名拼对。
但「屏幕」一旦它变成模型的上下文来源,风险可能远比想象的要大,尤其是那些采用云端模型的AI 工具,基本上自己做的任何事情毫无隐私可言,等于提供了在别人面前裸奔的条件。
「主动看」还是「偷偷看」
我把常见做法粗暴分成三档,方便大家判断自己在用的 AI输入工具处在哪一档:
1)显式截屏/手动投喂(相对可控)
典型是桌面端的「Take Screenshot」:我点一下,选一个窗口或区域,再发给 AI。
这档的关键是:我知道自己交出了什么。
但显然会比较麻烦,所谓的「摩擦」比较大。
2)读取活动 App/输入框内容(危险从这里开始)
很多「跨 App 听写」工具为了让你在任何地方都能说话输入,会用系统级权限去读当前画面的输入框、选中内容,甚至还会在后台看看剪贴板等。Superwhisper 文档里就把这些上下文来源写得很清楚。
这类能力常常依赖操作系统权限,比如: macOS 的辅助功能/权限体系,或者 Android 的无障碍(Accessibility)能力。
3)持续快照/时间线式记录(最危险)
这类不是「为了当下输入更准」,而是把整个屏幕历史当作可检索的记忆库。典型例子:
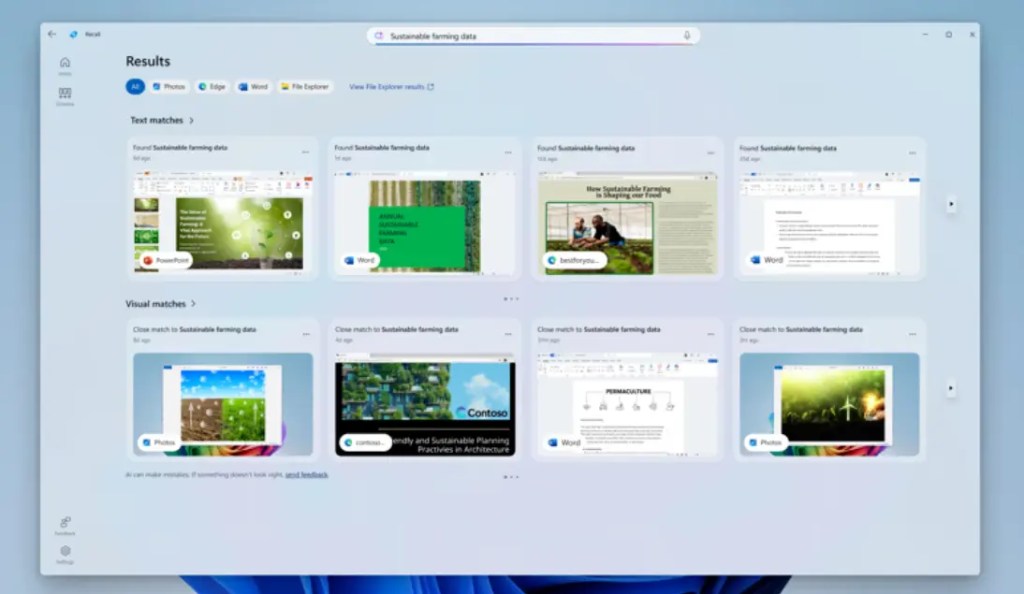
- Windows 以前提起的的 Recall(下图):以「snapshots」方式保存用户做过什么,并提供暂停/开关等控制。
- macOS 的 Rewind 这类「记录一切」App:媒体报道过它的核心卖点就是记录你在 Mac 上看过/做过的内容以便回溯搜索。
也不是「会不会上传云端」这么简单
很多产品会强调「本地处理」「不上传云端」。这当然重要,但远远不够。因为风险分布在三个层面:采集、存储、传输/处理。下面是我认为最要命的几类:
1)输入 A,AI 顺手把 B 也带走了
语音输入的真实场景是碎片化的:我们可能在回复 Slack,旁边开着客户合同、工资单、2FA 验证码、病历报告。
一旦工具获取的是「活动窗口」甚至「屏幕画面」,就很容易把没打算分享的东西当成上下文一起打包,生成隐私敏感的内容。
2)权限不可逆的「心理麻痹」
macOS 对屏幕录制权限的描述其实已经很清楚:可以控制哪些 App 允许录屏,而且如果允许第三方 App 录屏,它收集到的信息受对方条款和隐私政策约束。
很多用户第一次弹窗会认真看,几次之后就只想点「允许」了。之后它就长期存在,直到哪天想起来才去关。
3)企业/客户数据合规直接爆炸
在公司电脑上开会、写 PRD、看工单、处理客户资料,如果语音输入法/助手有屏幕上下文权限,那就是把「屏幕上出现过的一切」纳入了第三方软件的处理范围。
哪怕它声称不上传,光是「采集能力」和「潜在外发路径」就足够让很多组织的合规部门头大。
4)很难验证「它到底抓了什么」
最糟糕的一点:很多工具不会给我们一个「将要发送的上下文预览」,或者一个审计日志。
没有预览就没有可审计性。只能相信它的自我描述,而这在软件世界里属于最奢侈也最不靠谱的信任方式。 「零留存」「不保存」「不滥用」「不作恶」…… 我现在是一个字都不相信,我只看对方的信用等级和作恶的后果来决定。 对于一家新兴的小公司,尤其拿了点融资急于想证明自己的那种,完全不用给它任何隐私信用,这是最理智的。
我自己的取舍:把「上下文」当成高危权限对待
我并不反对上下文。相反,我之前文章就承认,现在的 AI 识别效果真的很理想:拼写准确、指代清晰、语气更贴合场景。像 Wispr Flow 这种「用有限屏幕上下文拼对名字」的思路,本质上就是在追求极低的输入摩擦。
但我的原则是:
- 默认关闭一切「自动屏幕上下文」(尤其是持续型、全局型)。
- 需要上下文时,用「选中文本」代替「整屏/整窗口」。
- 只在「我能接受泄露」的场景主动启用,比如写公开内容、写无敏感信息的草稿。
- 某些企业环境建议直接一刀切:公司机器不装、不授权,别拿同事和客户当实验材料。
另外,除了「看屏幕」,键盘记录,扫剪贴板,扫本地文件 都是非常危险的行为。 不能因为只要是AI需要「上下文」就能以此为借口,随便乱来。 这种事情已经不是单纯的工具使用原则了,可能有更广泛的参考意义。 如果有人以让我方便的名义,任意收集我的隐私,嘴上还说为我好,我就十分警惕。 是否要「牺牲隐私换取效率」,这点大家自行决定,但我的建议是要谨慎。
最后
AI 语音输入法要变好,理解语境「上下文」的确是很重要的。
但屏幕的隐私程度太高了。而且未必有能审计的系统。如果一个 AI 工具必须靠「持续看屏幕」才能显得聪明,那它多半不是聪明,只是单纯想多看些屏幕。
最后,我个人已经完全卸载了这类需要收集屏幕信息并发送到云端的AI 输入法。 这种不能审计的系统,在我不明确已知的情况下收集信息,背后又是一些拿了融资随时可以跑路的小公司,我认为这些都是危险的特征信号,不值得大家冒这个险,AI 大有有可为,但不是用在这个上面。
至于大家怎么想,见仁见智,欢迎告诉我。
