

我一直很喜欢 Obsidian 的核心理念:本地优先,万物皆文件,而且是单纯的 Markdown 文本文件。在这样的模式下,笔记完全属于我们自己,我们可以自由地搭配各种组件或插件,按照自己的习惯去定制操作和工作流。 而且,信息的保存备份同步,都在我们自己的控制下。
我之前介绍过 Obsidian 自家推出的 Web Clipper, 一个网页剪藏类的浏览器插件,同样秉承了上述的「文件中心」理念,把我们正在浏览的网页内容变为一个Markdown 笔记, 存入 Obsidian 的资料库中,而且还包含元信息。
最近 Obsidian 推出了 一个新的网站,Defuddle.md,Defuddle 是 Obsidian 本地文件生态系统里一个非常强力的工具,通俗来说,是 Obsidian Web Clipper 的网页版。
如果把 Obsidian 看作一个本地笔记的 OS, 我们之前介绍过 CLI(命令行接口),这个 Defuddle 更像Obsidian Web Clipper 的一个 URL 接口。
所以,在详解 Defuddle 之前,我们先快速回顾一下 Web Clipper。
Obsidian Web Clipper :网页变 Markdown
聊到 Obsidian Web Clipper,我个人觉得它最吸引人的地方,在于它早就超越了传统的网页保存抓取功能。
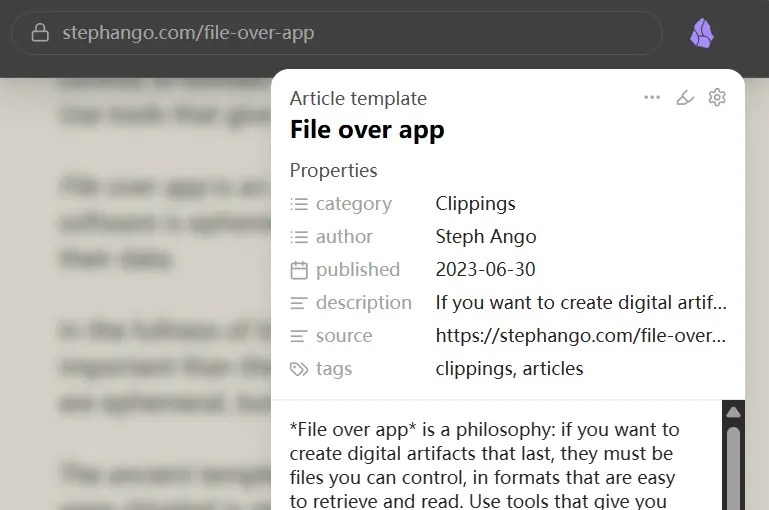
它不仅仅是把网页抓下来,更厉害的是它支持极其灵活的 Obsidian 模板。Web Clipper 能够提取网页里的各种元数据(比如作者、发布时间、甚至特定的页面元素)。更让我惊喜的是,它现在还支持条件判断、循环这些逻辑操作。这意味着,在采集网页的阶段,我们就可以按照自己的规则把内容整理好,直接变成干净、结构化的本地 Markdown 文件。
当然弊端是,如果用户不喜欢默认的整理模板,需要自己配置,这个过程可能会有一些门槛(其实可以让 AI 来配)。
但总的来说,Obsidian Clipper 完美契合了 Obsidian 的生态,让网页内容非常顺滑地融入我们个人的知识库。对于 Power User,又提供了自己捣鼓的空间。不要小看这些 Power User, 那么多 Obsidian 插件,大多都是用户自己捣鼓出来的。
Defuddle.md:专注清洗的抽取层
而 Defuddle 的出现,让我觉得 Obsidian 是把 Web Clipper 背后最核心的网页抽取能力单独开放出来了。
如果,大家是某个信息领域的资料收集者,调研者,数据分析者 …… 如果自己又能稍微捣鼓两下,又或者借助 AI(包括最近大火的小龙虾)捣鼓两下。 那么Defuddle.md 绝对是一个惊喜!
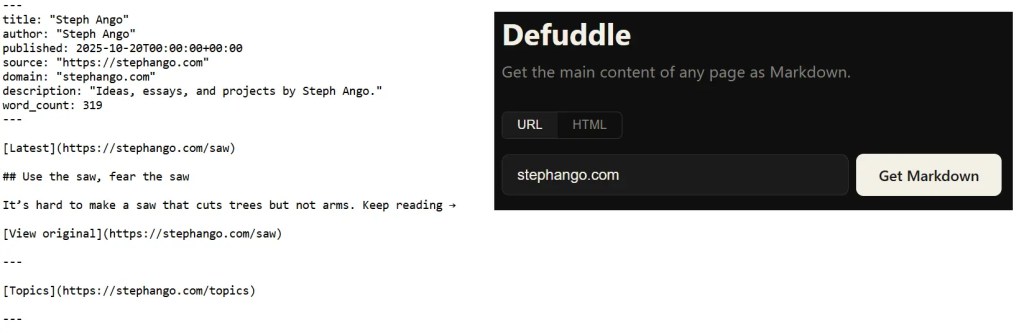
给 Defuddle 一个链接,它就能帮你清洗掉网页上的广告、推荐区等杂乱元素,尽量提取出干净的正文和结构化的元数据。它就像是一个专门负责把复杂网页转化为标准 Markdown 文本的净化器。 有了这个,任何人都可以做一个自己的 Web Clipper,而且不用隶属于 Obsidian。
Defuddle 提供几种访问方式。
- 普通用户,浏览器访问,输入需要转换的网页网址,查看清洗过的 HTML 或 Markdown
- AI Agent 或 开发者, 通过 URL 接口,获取清洗转换结果
- Obsidian 用户, 直接使用 Web Clipper 插件 即可(背后就是 Defuddle)。
其中最有价值的,我觉得就是 「URL 接口」,想象我是一个小龙虾,又聋又瞎,按用户要求收集访问网页非常痛苦,又是无头浏览器,又是被屏蔽,即使取得网页,里面的杂质噪音又很多; 现在好了,直接调用 Defuddle 一切解决。
而且,很重要的是,Defuddle 是开源的。我们甚至可以自己本地部署。这就很 Obsidian 了。 让 App 成为用户自己可以控制的系统,而不是把用户变成 App 的附庸。
最后
市面上,其实剪藏插件很多,其中不少的目的是锁定用户到某个特定App。 而 Obsidian Web Clipper 不同, 因为 Obsidian 理念是 File Over App。 现在,更进一步, Defuddle 被开放出来,大家可以直接用了,而且还是开源的。 所以,有点太阔绰了,反而不适应了。
如果对这类网页抓取(作为PKM重要组成部分)有兴趣的话,之前 Jina.ai 也提供了付费的 Reader API (下图)。Jina 是很多 AI 从业者的首选,现在则感觉有了一个免费开源的对手。当然,Jina号称是 AI模型 清洗抓取,还略有不同。

说实话,我现在反而开始担心 Defuddle 要被人滥用了(或者被屏蔽了)。
