-
知名的生产力工具 Raycast, 近期又在整什么新活? 他们推出的全新工具 Glaze 又是什么?

Raycast 不想只做启动器了
Raycast 这几年给我的感觉很奇妙。
我最早对它的印象,就是一个快速启动器工具,而且是苹果生态独占的。那时候 macOS Spotlight 还不是很强,而老牌启动器 Alfred 似乎又显得有点老了。所以当年 Raycast 横空出世的时候,确实像是一股新鲜血液。
后来我对 Raycast 的印象逐渐开始淡化,因为启动器工具(Launcher)本身不是一个特别厚重的叙事。它想成为一切功能的快捷入口,但这件事其实很难。它要和操作系统、浏览器、各种其它生产力工具竞争,同时还要整合它们,这是很吃力不讨好的事情。
比方说,苹果自带的 Shortcuts(Workflow)也在做类似的事情,Spotlight 这几年也得到了很大加强;很多浏览器开始集成命令面板和地址栏一键搜索;各种笔记工具有自己的快捷命令输入框;各种花式 AI 工具就更不用说了;还有一些剪贴板工具、窗口管理工具,也在分走 Raycast 的使用场景。
也许有人会说,Raycast 很全面,既能这样又能那样……但是根据我的经验,大多数人只有那些特别重要、特别频繁的动作,才需要快捷支持。有的人可能是剪贴板动作,有的人可能是搜索,有的人可能是窗口管理。大家未必有一个强烈需求,非要把所有东西统一到同一个入口里。这一点我后面会结合自己的例子再讲。
所以,我感觉 Raycast 一直不甘心只做启动器。尤其是拿了融资之后,单纯的启动器故事,很难再讲得更大。
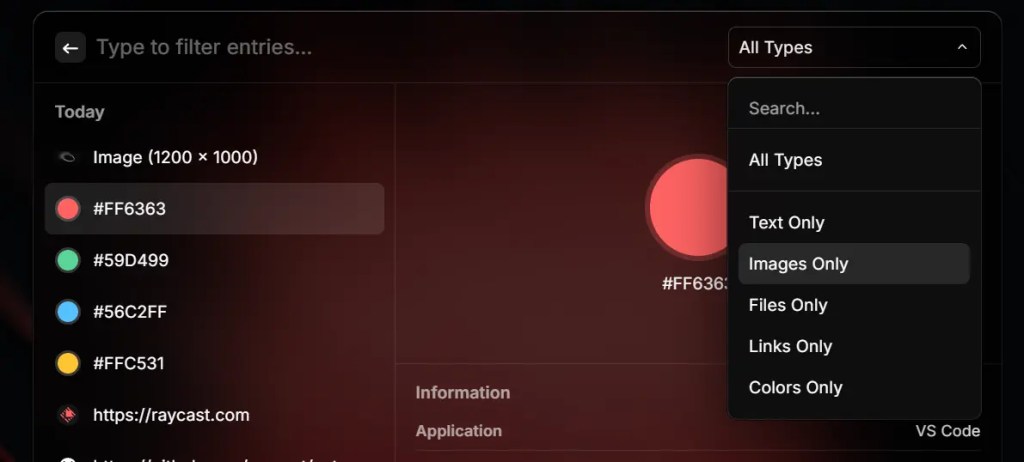
这就是我们前些时候看到 Raycast 开始推出 Ask AI 入口,并把它作为 Pro 版的一个付费功能。这很好地迎合了当时花式 AI 工具兴起的潮流,也算是把启动器向前推进了一步,开始瞄准 ChatGPT、AI 翻译、AI 查询工具这一类入口。
但最近 Raycast 的变化,已经不能再用简单的「启动器」或「入口」来理解了。
它似乎有了更大的野心。
它近期有三件事值得注意:
- 把自己从 Mac 专属工具变成跨平台工具,扩充用户来源。
- 把 AI 更深入地塞进系统操作入口。
- 推出 Glaze,用于「生成个人桌面 App」。
我们逐个来看一下。
Raycast V2:走向多平台
Raycast V2 最直观的变化是界面。
它适配 macOS Tahoe 的视觉风格,Root Search、AI、文件搜索、快捷键、Quicklinks、Snippets、Tags、Dictation 等入口都重新整理过。
同时,新增的 Windows 版本也进入了 public beta。我已经安装试用了。
官方技术文章里说,V2 是一次跨平台重写,混合了 TypeScript、Swift、C#、Rust、Node 和 React。它既不是纯原生,也不是简单套一个 Electron 壳。
早期得益于 Mac 生态独占,Raycast 最吸引人的地方,就是它非常轻,非常快,非常像系统的一部分。一旦重构之后出现更高内存占用、更明显的 Web UI 痕迹,或者某些 V1 功能暂时缺席,老用户可能会不满。
我试用 Windows 版本时,刚过 5 分钟,就意识到一个经典问题:macOS 上可能不明显,但 Windows 上不少套壳移植 App 都容易在这里翻车,那就是屏幕 DPI 适配。
我手上这个版本,会造成部分界面在某些设置了 DPI 缩放的大屏幕上不能完整显示,这就让实用性大打折扣了。希望后续能尽快修正。
另外,macOS 上很多经典实用的用例,在 Windows 上其实早就被其它工具占领了。
比如我用 Ditto、PowerToys,有的人还用 Everything。Windows 自带的窗口分屏管理也不错。Windows 用户似乎早就熟悉了快速把事情搞定的生产力哲学,不太喜欢过分精致的统一入口,也不一定欣赏那种整齐优雅的感觉。大家主要还是集中在把事情搞定上。
Ditto 很丑陋,但是很实用。Windows 自己的一些快捷键只要熟练了,也根本不需要什么优雅界面。文件搜索就更不用说了,Everything 的惊人实力大家也是知道的,只要不太介意界面是否漂亮。
尽管如此,我还是希望 Raycast 可以做出一个很好的示范,给 Windows 用户提供更多选择,尤其是那些刚入门生产力工具的用户。
还有就是,很显然,多平台的 Raycast,也是在为后面的 AI 和 Glaze 铺路。
AI:Raycast 不只是一个聊天框
很多软件都在加 AI,早期大多都是类似 ChatGPT 的套壳聊天框。Raycast 最早也类似,但现在 Raycast 的 AI 路线有点不一样。
现在的 Raycast 不是只放一个聊天窗口,而是把 AI 放进命令系统里。
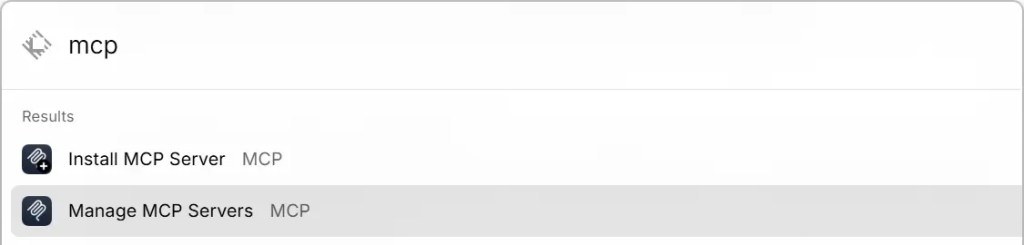
Quick AI、AI Chat、AI Extensions、MCP servers,这些东西组合在一起,意味着 AI 不只是回答问题,而是可以拉取上下文、调用扩展、跨应用执行动作。
有点像在浏览器里对着具体的 Tab 发问,对着某篇笔记、某个操作界面、某个 Todo 任务发问。官方给出的例子包括创建 Linear issue、搜索代码库等动作。
这其实很接近我理解中的「AI 操作层」:在某个入口里直接说出目标,让 AI 去调用本机和第三方工具。
听起来很理想,是吗?
但是,过去 Raycast 执行的是确定命令。我按下回车,打开 App,复制文本,搜索文件,结果很明确。现在如果想让 AI 更准确地识别意图,还是少不了选择命令或菜单。由于它集成了太多功能,结果反而有点更麻烦了。
比方说,我使用 Perplexity 查询时,以前有个快捷键,可以一键呼出 Perplexity / PPLX 界面,输入查询,已经形成肌肉记忆了。
现在变成:呼出 Raycast,输入或选择 PPLX,回车,再输入内容。这样一圈下来,到底意义何在?
又比方说,原本做网页内容总结,我们可以通过集成 Gemini 的浏览器,或者 Atlas、Comet 这类浏览器,在当前页面里一键唤起 AI。现在则是呼出 Raycast,输入指令,粘贴网址。当然,也可以用浏览器插件简化,但交互上显然还是更绕了一点。
我的意思是,让 AI 发生在上下文中是最好的,而不是另起一个统一接口,除非是一些非常通用的查询。
让 AI 发生在上下文里,这是目前所有主流软件或网站都已经在做的事情。即使不是发生在第一现场,Codex、Claude Code、OpenCode 也有很好的 AI 接口。所以 Raycast 处在一个很尴尬的 AI 入口位置,我个人不太看好它作为 AI 统一入口的长期位置。
Glaze:Raycast 真正的新玩具
Glaze 是 Raycast 最新推出的 AI App builder,之前有过预告和内测,现在终于公开可用了。
Glaze 的核心卖点是:用自然语言描述需求,Glaze 帮我们生成一个真正运行在电脑上的桌面 App。

Glaze 官方强调,生成的 App 可以运行在本机、离线使用、访问文件系统、支持快捷键、菜单栏和后台进程。目前它要求 macOS Tahoe 和 Apple Silicon,未来计划支持 Windows 和 Linux。
我下载了 Glaze,还没有真正用它生成 App,只是先看了看它的 App Store,也就是别人把生成的 App 放上去、供大家公开下载的地方。
挺有趣,但目前看下来,更多还是一些小工具,有些还挺简陋的。
不过我知道,真实需求往往就是很小:一个收据整理器,一个 Markdown 文件目录生成器,一个菜单栏计时器,一个本地截图归档工具,一个团队内部 review 面板,一个只服务某个项目的资料 dashboard。、
很多人都有自己变通的生产力方式。以前这些小需求可能用脚本、快捷指令、Excel、Notion、AppleScript、Python 或者各种临时方案勉强解决。现在如果可以通过 Glaze 打包成一个本地 App,然后立刻使用,这确实是一件好事。
而且 Glaze 和 Raycast 天然契合。Raycast 是入口,Glaze 是工具生成器。用 Glaze 做出来的小 App,未来很可能可以通过 Raycast 启动、搜索、调用,甚至嵌入到 AI workflow 里。
这是一个很好的点子。
但我也不会把 Glaze 说成是什么特别颠覆式的发明。它更像是 GPTs、Skills 这类东西的 GUI 包装。对特定人群很实用,但也不必把它说得过于神奇。
这类生成出来的小工具,质量往往良莠不齐,后续维护也是个问题,试想我怎么敢把几百条书签放在一个 莫名其妙没有经过时间和用户检验的 Glaze 小工具里面?尤其是当一个小工具真的被用户依赖之后,它就不再只是一个随手生成的玩具,而会变成一个需要长期维护的软件。
但总的来说,Glaze 是个很好的尝试,尤其是 Glaze App Store 提供了各种可能性。
最后
Raycast 的发展很有趣,但后面可能也会越来越难。
尤其是拿了融资之后,它就不能再只是一个「小而美」的工具,而是必须讲出一个更庞大的叙事。
现在来看,Raycast 确实很会整活,但我也希望它不要忘记初心。我见过很多类似例子,前期吹得很大,最后草草收场,或者被收购,用户被扔在了一边。 什么 Evernote?我有说过吗?
希望 Raycast 可以走得更远。至少,它可以继续给大家带来更多工具选择和启发。
Raycast 官网
Raycast Glaze 官网
-
【速报】Notion Mail 宣布关闭:邮箱正在从 inbox 变成 AI agent 的输入流

Notion 官方已经确认,Notion Mail 将在 2026 年 9 月 22 日正式关闭,Web、桌面与 iOS 客户端都会停止服务。从 2025 年 4 月上线,到 2026 年 9 月关停,这款产品大约只存在了 17 个月。
官方给出的理由,并不只是普通的「产品调整」,而是一个更激进的选择:随着 Notion Agents 能力提升,越来越多用户已经不再亲自打开收件箱处理邮件。公司决定把资源集中到 AI Agent 路线,而不是继续维护一个 inbox 产品。
以前我看到的所谓智能邮箱,大多只是借助 AI 筛选、分类邮件,形成一个更聪明的 inbox。比如 HEY、Superhuman 这类产品,甚至 Gmail 这样的主流邮箱服务,也在朝这个方向演进。
但最近的趋势更加激进:邮箱不只是变聪明,而是直接变成 Agent Mail。人甚至不再需要亲自查看收件箱,邮件处理全部交给 AI。
一个只活了 17 个月的邮箱实验

2025 年 4 月,Notion 推出 Notion Mail,试图把邮箱纳入自己的生产力版图。它并不是一个独立邮箱服务,而是与 Gmail 深度同步的 AI 邮件客户端:邮件实际仍保留在 Gmail,Notion 提供的是数据库式视图、自动标签、snippet 模板、状态管理和 AI 辅助写作等增强层。
所以更准确地说,Notion Mail 仍然是一个增强型邮箱客户端。
从产品想象上看,它延续了 Notion 一贯的路线:不是只给用户一个应用,而是把信息对象重新结构化,让邮件也能像页面、任务和数据库一样被重新编排。
我之前有过文章介绍,2024 年 2 月,Notion 收购了以隐私和端到端加密著称的生产力平台 Skiff。后者提供文档、云盘、日历和邮箱服务。收购完成后,Skiff 产品进入关停和迁移期。因此,外界很自然地把 Notion Mail 视为这次收购后的延伸。
但一年多之后,故事急转直下。
2026 年 6 月,Notion 在帮助文档中明确宣布,Notion Mail 将在 9 月 22 日关闭。用户从 6 月 25 日起,可以导出草稿、定时发送邮件、snippet、自动标签规则和自定义视图等仅存在于 Notion Mail 内的数据。9 月 21 日之后,未导出的内容将被永久删除。
当然,Gmail 中保存的邮件本身不会丢失。真正需要注意的是,9 月 22 日之后,不会再有新邮件同步进入 Notion Mail 的数据库视图。用户真正需要处理的,也不是 Gmail 邮件本身,而是 Notion Mail 内部那些增强数据的导出。
所以这件事不必过度恐慌,但也不能完全忽略。
Notion 对外讲述这次关停时提到:随着 Notion Agents 能力增强,越来越多用户已经把邮件工作流交给 AI Agent 处理,而不再通过传统 inbox UI 自己逐封点开邮件。
我们也能看到,Notion 最近一年讲的核心故事就是 AI Agent,很多产品叙事都在向这个方向靠拢。从 Notion 的逻辑看,维护一个跨平台邮箱客户端的成本很高,而把邮件处理能力沉到 AI Agent 基础设施里,则可以同时服务日历、任务、文档和自动化工作流。
当然,这套叙事也有一个明显的公关优势:它把 Notion Mail 的结束包装成「产品升级」,而不是一次普通的产品关停。
从 HEY 到 Agent Mail:邮箱行业的三代演化
如果把 Notion Mail 放回整个邮箱行业,会更容易理解它为什么在这个时间点下线。
过去几年,撇开传统邮件客户端不谈,智能邮箱大致经历了三代演化。

第一代是 UI-first 的「重做收件箱」。HEY 是代表性产品,它通过 Screener 让用户先审核陌生发件人,再把邮件拆进 Imbox(不是 Inbox,Hey 自创了一个词)、The Feed 和 Paper Trail 等不同区域。本质上,它是在用一套强观点的界面设计,帮助用户重新夺回邮箱控制权。
这类产品相信,邮件问题首先是交互问题。只要 inbox 设计得更合理,人就能重新管理好注意力。其实,很多非邮件产品也遵循类似逻辑。这个「以人为本」的方向我一直很尊重。

第二代是 AI assistant 型产品。Superhuman、Shortwave、Gmelius、Lindy 等工具,则开始在现有邮箱或工作流之上叠加 AI 能力:自动总结长线程、给出回复草稿、安排 follow-up 提醒、识别优先级、与日历或 CRM 同步。
AI 让用户处理同样数量的邮件时更快、更省力,但用户依然需要每天打开 inbox。只是旁边多了一个勤快的助手。
第三代是 Agent-first 型产品。越来越多产品直接以「AI email agent」或「autonomous agent email software」来定义自己。它们的卖点不再是更漂亮的收件箱,而是 AI Agent 自动整理邮件、抽取结构化信息、生成回复、更新 CRM、触发工单。只有在高风险场景下,才把决策重新交给人工审核。
在这套逻辑里,邮件不再是你每天反复打开的应用,而是一种被 AI Agent 持续监听、解析和行动的信息输入流。
收件箱正在退居幕后
Agent Mail 一类的新工具,标榜的是「让 AI 先管理邮箱」。

无论是各类自主邮件 agent 工具目录,还是 2026 年大量「AI email agents」榜单,强调的能力都非常一致:自动分拣邮件、提取任务、生成或直接发送回复、与销售和客服系统同步,并在低风险场景中尽可能减少人工介入。
在这里,收件箱不再是主战场。真正的竞争点,变成了 AI Agent 对上下文的理解、对组织知识的调用,以及何时应该把控制权还给人类。
顺便一说,国内某家大厂最近也跟进了这波 Agent Mail 趋势。
我真正担心的部分
这次事件还有一个容易被忽略的背景:Notion Mail 的技术和团队背景,部分来自 Skiff,而 Skiff 原本讲述的是一个完全不同的故事。
Skiff 的核心标签是隐私、端到端加密和去平台化。它试图提供一个不依赖大平台的工作套件,也试图重建一套更独立、更私密的邮件基础设施。
这意味着,Notion 收购 Skiff 之后,并没有真正延续「重建底层邮件基础设施」的隐私路线,而是更务实地把收购转化为产品能力和人才资产。当 AI Agent 成为新的重点后,这个取向更加清晰:Notion 要的不是做一个最独立、最私密的邮箱产品,而是让用户的邮件、日历、文档和任务都能流进同一个 AI 驱动的工作流中。
从商业角度看,这当然可以理解。
但是,「隐私优先」和「数据自我控制」这套叙事,似乎正在被挤到越来越边缘的位置。越是把邮件交给 AI,越应该明确哪些东西可以自动化,哪些东西必须保留在人自己手里。
Notion Mail 所代表的这种升级,更适合工作场景中套路固定的邮件往来,也适合那些已经成形的组织工作流。比如销售跟进、客服分派、会议安排、状态更新、CRM 维护,这些场景本来就有明确流程,也更容易设定规则和边界。
但在私人邮件场景里,它恐怕还不太适合,也不应该轻易让 AI 全面接管(我已经脑补出了邮件 提示词注入攻击窃取个人信息了)。
AI 可以帮助处理邮件,但不应该默认接管所有私人通信。工作流可以自动化,个人边界和数据控制权仍然要留给用户自己,这也是我一贯的立场。
-
把剪贴板变成 AI 收件箱:我最近整理信息碎片的方法

我已经很少使用剪藏类插件了
最近我在试一种很朴素却很顺手的信息整理方法:浏览网页时,先不要急着分类或收藏为笔记,更不要打开某个复杂的知识管理系统,我会把看到的内容先丢进剪贴板历史里,对,就是一股脑都复制到剪贴板里。
顺便一说,这不是什么心血来潮,临时拼凑的技巧,我已经实践了6,7个月了,才在这里分享给大家。
这个方法的前提很简单:我每天会浏览很多网页,包括产品文档、博客文章、论坛讨论、工具说明、GitHub issue、用户反馈、新闻资料、摘要,甚至一些社交媒体里的短句。过去我总想在看到一段内容时,就立刻判断它应该放到哪里:是项目资料,还是产品灵感,还是写作素材,还是某个主题研究的一部分。
这种刚看到内容就开始分类的动作,其实很打断心流。
阅读时,我不应该过早切换到整理状态。阅读本来应该保持流动,一旦开始思考「这段内容放在哪个文件夹」「要不要新建一篇笔记」「标题该怎么写」「标签用哪个」,阅读节奏就被彻底打断了。
所以我现在的第一步过程非常「粗暴」:看到有用的内容,就直接复制。

先复制,不整理
这里的关键不是复制全文,这点很重要。
无脑复制全文,本质上还是另一种通篇收藏。多数时候,我只是复制一段文字,有时候只复制一句话。有时候是网页里的观点,有时候是某个段落里的描述,有时候只是一个让我想起别的问题的表达。
复制之后,我不马上处理,也不马上写进 Obsidian 或其他笔记工具,而是继续阅读下去。
我用的是 Ditto 这样的剪贴板历史工具。Ditto 是 Windows 下的工具,我用了很多年。macOS 下也有类似的 Paste 等工具。它们会把复制过的片段临时存起来。等浏览告一段落,再从 Ditto 里把最近一批剪贴板内容一次性导出或粘贴出来,生成一个很大的文本块。整个过程都是快捷键操作,并不复杂。
这个打包在一起的「大文本块」通常很乱。里面可能有重复内容,可能有网页残留格式,也可能是标题和正文混在一起,不同文章之间未必有明确划分。
以前我一定不会这样做,因为保存的结果根本没法直接用,还要花很多心思整理。现在有了 AI 之后,我反而觉得,这种杂乱但有一定筛选痕迹的文本块,正是 AI 适合处理的材料。
我只负责在阅读时判断什么值得留下,AI 则负责把这些碎片信息整理成可用的笔记。

把大文本扔给 AI
我现在会把这份大文本扔给 Codex,或者其他支持文件读写的 AI 客户端,比如 OpenCode、Claude Code 之类都可以。
重点不是一定要使用哪一个客户端,而是它要能根据预设规则,把一大堆杂乱的信息拆成多篇可读的 Markdown 笔记,并保存到指定位置。
这一步我通常不会只说一句「帮我整理一下」,这可能是最糟糕的指令,就像和老板和员工说,「帮我弄一下」,这是什么意思?。
我会预先准备一个技能、规则文件,或者 prompt,让 AI 按照固定方式工作。每个人可以按照自己的习惯和领域,给 AI 设置不同要求。我的基本规则大致是:
- 先识别不同主题,不要把明显不相关的内容混成一篇。
- 每个主题生成一篇独立的 Markdown 笔记。
- 笔记标题要根据内容自动概括,或者识别出剪贴板内容里已经存在的标题文本。
- 不要随意改写原文,重要表述保留摘录状态,并串联在一起。
- 将结果保存到指定目录,比如
Inbox/Clipboard/,或者某个分类文件夹。
这样做以后,剪贴板就变成了一个很轻量的 AI 收件箱。
我不需要在浏览时停下来建笔记。复制动作本身就是采集动作。等到后面统一处理时,AI 再帮我做分割、命名、归类和初步摘要。

标签不要靠临场发挥
这套流程真正变得稳定,是从我开始给 AI 预先设置标签规则之后。
如果完全让 AI 自由发挥,它很容易生成一堆看似合理、但实际不可维护的标签。比如今天生成
productivity,明天生成productivity-tools,后天又来一个workflow。这些标签单独看都没错,但长期会把笔记系统搞乱。所以我更倾向于给它一张固定标签表,或者至少给出明确的标签规则。
下面只是一个例子,不是我的实际标签表:
allowed_tags:- ai- workflow- pkm- writing- product-research- investment-research- obsidian- local-first- automation- reading-notes然后要求 AI:
- 只能从
allowed_tags中选择标签。 - 每篇笔记至少 1 个标签,最多 4 个标签。
- 如果没有合适标签,使用
inbox,不要创造新标签。 - 如果内容涉及多个主题,优先选择最具体的标签。
我更希望 AI 根据内容理解来分类,而不是随手发明一套新的元数据。
这样生成出来的笔记不会特别完美,但基本能进入我的系统,而不是变成另一批需要整理的垃圾。
也不要对标签有过度苛刻的要求。因为有了 AI 之后,完全可以事后按照新的标签规则,对已经保存的文件重新分类。换句话说,不要苛求一次到位。
这比直接保存网页更适合我
很多工具都支持网页剪藏,但我一直觉得网页剪藏有一个问题:它太「无脑」了。
收藏网页很容易带来一种错觉,好像内容已经被处理过了。实际上,它只是被保存了,甚至可能从来没有被完整读过一次。
剪贴板方法反而更克制。因为我复制的是当下注意到的部分,而不是整页网页。它天然已经经过第一轮粗筛。即使复制得很随意,也比完整网页更接近我的真实兴趣点。
换言之,网页剪藏保存的是网页,剪贴板保存的是注意力。它更接近我当时真正注意到的东西。这里面已经包含了一层筛选和判断。如果能顺手加上批注,就更好了。
浏览时只负责阅读和发现,AI 处理时负责拆分,笔记系统负责长期保存。每个环节只做一件事,反而比一边阅读一边整理更稳定。

进阶:让 AI 定期做二次整理
在这套流程基础上,还可以加一层定期总结。
比如每周两次,让 AI 扫描
Inbox/Clipboard/里最近新增的笔记,生成一篇阶段性总结。如果是按周总结,还可以让 AI 找出更高层次的趋势。比如这一周我复制了很多关于某类 AI 工作流的材料,那它就应该提醒我:这不是孤立兴趣,而是一个正在形成的研究方向。
这个总结不一定要自动写进正式笔记。它可以先放在
Review/Weekly/文件夹里,作为二次加工的入口。真正有价值的内容,再进入项目笔记或者 backlog。还有一个很实用的地方:一旦标签分类规则发生改变,可以事后让 AI 对存量文件重新分类。
这在以前是无法想象的工作量。但是有了 AI 之后,这件事不再复杂,反而很实用。这也是一种二次整理。
我现在更愿意把 AI 当成一个助理,而不是一个代替我思考和阅读的大脑,我现在非常反感「第二大脑」的说法,一般当作低劣的营销噱头来看。AI 不需要也不应该替我决定什么重要,但它可以帮我把散落的内容粘合起来,分堆、贴标签,并生成初步索引。
工具为次,理念为先
这套方法最有价值的地方,不是 Ditto,不是 Codex,甚至都不是具体的 prompt。
它真正改变的是信息整理的顺序。
过去常见的顺序是:
看到信息 → 判断价值 → 找位置 → 建笔记 → 写标题 → 打标签 → 保存
稍微偷懒一点,则变成:
看到信息 → 保存收藏 → 想着以后整理 → 大概率吃灰
现在变成:
看到信息 → 复制 → 继续阅读 → 复制 …… → 批量交给 AI → 自动拆分 → 自动打标签 → 定期回顾
之前要求我在阅读过程中不断切换身份:一会儿是读者,一会儿是资料管理员,一会儿是编辑,一会儿又是项目经理。后者则让我专注眼前的阅读,把一些琐碎的整理动作规则化,并交给 AI 自动处理。
当然,这不是一个完美系统。它仍然需要定期清理,也需要不断调整标签规则。AI 也会误判主题,偶尔会把应该分开的内容合在一起,或者把一个片段解释得过头。
剪贴板原本只是一个临时缓存。加上剪贴历史工具和 AI 之后,它可以变成一个低摩擦的信息入口。
这大概也是我现在对 AI 工具最实际的期待:不是替我思考,而是把我已经注意到的东西,按我设定的规则整理好就行。
-
压缩个人的知识线索,把 Markdown 批注重新找回来:Obsidian SideBar Highlights 的侧边栏工作流

关于 Markdown 批注
我一直有给笔记做批注的习惯。
有时候只是把一句话高亮标出来,提醒自己以后再看;有时候则会在后面写一段自己的评论,记录当时为什么觉得这句话重要,或者它和我正在研究的某个问题有什么关系。
这件事听起来很小,但如果长期阅读、写作、做研究,或者经常整理资料,就会发现:高亮和批注其实不是装饰,而是一种非常基础的信息加工动作。对于很多基于 PDF 论文工作流的人来说,这已经是日常操作。只不过我面对的不是 PDF,而是 Markdown 笔记。
毕竟原文可能只是网页摘录,也可能来自别人的观点,批注才真正属于自己。
过去很长一段时间里,我对 Markdown 语法的用法了解得并不深,所以一直用最简单的方式处理这类需求。比如用「加粗」表示重点,用「斜体」表示补充说明,或者直接在原文下面另起一行,写上「我的看法」。(很粗糙的做法,是吗?)
这种方式当然也能用,而且很直接。但它不够清晰。
一篇文章里如果到处都是加粗,很快就分不清哪些是原文重点,哪些是我自己的判断;如果评论直接混在正文里,过一段时间再打开,就会有点像考古:当时这句话到底是引用,还是我自己写的?这段补充是临时想法,还是已经整理过的结论?
后来我才知道,Markdown 生态里其实有一些更适合批注的写法。
比如在很多 Markdown 工具里,可以用:
==高亮部分==用来表示高亮内容。
在 Obsidian 里,还可以用:
%%批注内容%%用来生成备注或注释。
这比单纯加粗要明确得多。高亮就是高亮,批注就是批注,正文、重点和个人评论之间开始有了边界。
再后来,我又查到了一种叫 CriticMarkup 的标注语法。它看起来比普通 Markdown 稍复杂,但表达能力也更完整。它不仅可以表示新增内容、删除内容,还可以表示替换、评论和高亮。比如:
{++新增内容++}{--删除内容--}{旧内容~>新内容}{>>评论内容<<}{==高亮内容==}它的思路很像一种纯文本版本的「修订模式」。
过去我们在 Microsoft Word 里审阅 DOCX 文件时,会看到某个人增加了哪句话,删除了哪一段,旁边还有评论气泡。CriticMarkup 想做的事情,某种程度上就是把这套审阅动作搬回到纯文本里。
这点对我很有吸引力。因为它不依赖某一个特定软件,也不一定要进入复杂的在线协作系统。只要文本本身还在,标注信息就依然还在,不会被锁进某个云端 SaaS 的评论数据库里。
当然,CriticMarkup 原本更偏向多人协作场景。几个人共同修改一份文章、文档或手稿,需要知道谁删了什么、谁加了什么、哪些地方还有争议。这套逻辑和 Word 的审阅功能有点像,只是表达方式更朴素,也更接近 Markdown 用户熟悉的纯文本工作流。
但我后来意识到,它也不一定只能用于多人协作。到了今天,另一个很常见的批注者,可能就是 AI Agent。
比如我写完一段文章,让 AI 帮我 review,它不一定非要直接改掉原文。更好的方式可能是:保留原文,让 AI 用某种批注语法标出哪里表达不清、哪里逻辑跳跃、哪里可以补充例子。
这样我既能看到建议,又不会失去对文章的控制权。这和我一直喜欢的本地优先工作方式很契合。
我不太喜欢把所有资料都塞进一个在线平台,再依赖平台提供的评论、任务、协作和版本功能。它们确实强大,但也会让一份原本简单的文本变得越来越重。
相反,如果批注本身就能留在 Markdown 文件里,那么无论我用 Obsidian、VS Code,还是其它本地编辑器打开,它都仍然是可读、可检索、可迁移的。
这时候,Markdown 也可以变成一种轻量的审阅格式。
我可以给摘录加高亮,可以给段落加评论,可以让 AI 留下修改建议,也可以在以后重新回到这些批注里,判断哪些想法值得展开,哪些只是当时的一闪而过。
不过,高亮和批注只是第一步。
真正的问题是:当我们有了足够多的笔记高亮和评论批注之后,下一步该怎么办?
一开始,几条高亮很好处理。它们就躺在原文里,打开笔记就能看到。
但当一个资料库里有几十篇文章、几百条摘录、上千处高亮之后,情况就变了。高亮不再只是「醒目的黄色标记」,而会变成一堆散落在不同文件里的信息碎片。
你曾经觉得重要的句子,可能已经被埋在很深的目录里;你写过的评论,可能再也不会被重新看见。
这时候,我们需要的就不只是「能高亮」了。
我们需要的是:能把高亮和批注重新收集起来、整理出来,变成可以回顾、筛选、重组的材料。
也就是说,批注的价值不只在于标记当下,而在于它们能否在未来再次浮现出来。
这也是我后来开始关注 SideBar Highlights 这类 Obsidian 插件的原因。
SideBar Highlights 登场
我试过很多 Obsidian 插件,但真正能留下来的并不多。
有些插件野心太大,什么都想做,界面复杂,设置复杂,工作流也复杂。还有一些插件则刚好相反,功能太薄,几乎没有真正解决问题。
所以我后来对 Obsidian 插件有一个很朴素的判断标准:它最好只解决一个清晰的问题,但要把这个问题解决得足够顺手。
对于高亮和批注这件事,我还有一个附加要求:批注信息必须保留在原来的 Markdown 文本文件里,不要另外开一个数据库出来。
因为一旦批注被单独存到某个插件数据库里,它就开始脱离原文了。
今天这个插件还在,当然一切都好;但如果以后插件停止维护、换设备、迁移笔记库,或者我只是想用 VS Code 打开这些 Markdown 文件,那些批注信息还能不能跟着走,就变成了问题。
我不希望自己的阅读痕迹被锁在某个插件里。
我更希望它们就是文本本身的一部分。高亮也好,评论也好,任务也好,都应该和原文待在一起。这样哪怕脱离 Obsidian,哪怕以后换一套工具,这些信息依然可以被看见、被搜索、被处理。
SideBar Highlights 基本上正好符合我的需求。
侧边栏高亮列表
最核心的功能当然是侧边栏列表。
打开一篇笔记后,SideBar Highlights 会把里面的高亮内容集中显示出来。对于长文来说,这个体验非常直接。你不用在正文里滚动查找,只要看侧边栏,就能知道这篇笔记里有哪些地方曾经被你标记过。但需要注意的是,这里所谓的高亮,是指 == ,%%,和脚注(包括 尾注 和 inline);但并不支持 CriticMarkup 语法, CriticMarkup 太专业了,更适合协作,而不是个人批注使用。
这有点像给长文自动生成了一份「个人重点目录」。
普通目录显示的是标题结构,而 SideBar Highlights 显示的是阅读结构。标题是作者安排的,高亮是我自己留下的。两者合起来,才更接近一篇文章真正被理解和处理过的样子。
也可以把它理解成一份围绕个人阅读痕迹生成的侧边目录。
你不需要重新阅读整篇文章,就能先看到自己当时标出来的重点。看到某一条内容时,也可以直接跳转回原文所在位置。
这就很适合二次阅读。
第一次阅读时,我可能只是顺手高亮;第二次打开时,我不一定想从头读到尾,而是想快速回到那些曾经触动我的地方。
SideBar Highlights 提供的侧边栏列表,就像是把这篇文章压缩成了一组可以跳转的线索。
颜色和 Collection
更进一步,SideBar Highlights 不只是显示高亮。
如果你给不同类型的批注使用不同颜色,它也可以帮助你区分这些内容。
比如我可以把事实信息标成一种颜色,把值得引用的句子标成另一种颜色,把需要追问的问题标成第三种颜色。这样一来,高亮就不只是「我觉得这里重要」,而可以进一步变成一种分类动作。
如果想把散落在各篇笔记里的标记聚合到一起,除了通过颜色区分,也可以通过 Collection 重新组织。
Collection 可以理解成一个分组,或者类似文件夹结构,用来把选定类型的批注汇聚到一个地方。
不过这里也要注意:Collection 会保存到专门的外部文件中,所以它和直接留在 Markdown 原文里的高亮不完全一样。不是说 Collection 不能用,而是它已经不是完全嵌在原 Markdown 文件里的信息了。从数据迁移和长期可控的角度看,这里多少会有点风险。
所以我个人觉得,如果没有强烈需求,未必一定要用 Collection。只靠 Markdown 原文里的高亮、注释和颜色分类,对很多个人使用场景来说,已经足够了。
筛选和过滤
有了高亮列表,并不意味着我一定要一次看完所有高亮,而可以只看某一类标注。
比如只看某种颜色,只看某一组 Collection,或者只看当前阶段真正关心的内容。
当高亮越来越多之后,新的问题很快就会出现:信息太多了。
原来我们是担心重要内容被正文淹没,现在又变成了高亮本身太多,需要继续筛选。
SideBar Highlights 支持多种筛选语法。对多数个人使用场景来说,已经足够。
比如我只想看「问题类批注」,或者只想看某个项目相关的高亮,就不必再从全部标记里手动翻找。它本质上是在高亮之上,又加了一层索引能力。
从正文,到正文的索引,再到索引的索引,某种程度上,这正是我们学习和整理知识的过程:从复杂材料中抽象出一个压缩模型。LLM 理解语言世界的方式,或许也有点类似。
默认隐藏的 Task Tab
还有一个容易被忽略的小功能:SideBar Highlights 里有一个默认隐藏的 Task Tab,我也是无意中发现的。
打开之后,它可以把 Markdown 笔记中的代办任务(
- [ ]语法)汇聚到一起显示。也就是说,那些散落在不同笔记里的任务,不再需要靠手动翻找了。
这点和高亮列表的逻辑其实是一致的。
高亮负责把重要内容从正文里提取出来,Task Tab 则负责把后续行动从笔记里提取出来。这样一来,一边批注,一边生成后续任务,也就变得很自然。
比如我在阅读时看到一个问题,可以在旁边写下评论;如果这个问题值得继续研究,就顺手写成一个 Markdown 任务。之后再回到 Task Tab,就能看到这些从阅读中自然生长出来的行动项。
更妙的是,这些任务仍然留在 Markdown 里。
不一定需要额外的待办工具,而且任务和上下文天然绑定在一起。它不是孤零零的一条 todo,而是和原文、摘录、评论、高亮待在同一个语境里。
这对我来说很重要。
很多任务管理工具的问题是,任务被抽离得太干净了。你只看到「继续研究某某问题」,但过了几天,可能已经忘了这个任务是从哪篇文章、哪句话、哪个想法里来的。
而如果任务本身就留在 Markdown 笔记里,它的上下文就不会丢。
最后
所以我觉得,SideBar Highlights 的意义更像是把高亮变成了一种可操作的对象。
以前高亮只是留在原文里的颜色痕迹,现在它可以被集中查看,可以跳转,可以筛选,可以分类,也可以放入 Collection。
它开始变成一种真正的索引,就像标签一样;也是一种回到原文的入口,就像标题目录一样。
更重要的是,我一直觉得这是一种把长文,或者大量笔记,重新压缩成个人可理解知识的方法。
Markdown 给了我一个足够简单、足够稳定的文本底座。高亮和批注让我在这个文本底座上留下自己的阅读痕迹。而 SideBar Highlights 做的事情,就是把这些痕迹重新收集起来,让它们不只是躺在原文里,而是重新变成可以被看见、被筛选、被组织、被再次利用的材料。
这也是我喜欢这类小插件的原因。它只是围绕一个很具体的问题,并给出完美的的解决,把那些散落在 Markdown 里的高亮和批注压缩成为个人的「知识线索」。
SideBar Highlights 官方开源地址
https://github.com/trevware/obsidian-sidebar-highlights
直接在Obsidian 插件社区搜索 SideBar Highlights,就能安装。
-
【速报】Hermes Agent 终于有了官方桌面版:AI Agent 开始从命令行走向真正的工作台

最近 Nous Research 正式推出了 Hermes Desktop,也就是 Hermes Agent 的官方桌面版。
部分朋友可能对 Hermes Agent 还比较陌生,我简单介绍一下背景。前段时间,「小龙虾」(OpenClaw)这个 AI 个人助理工具火了一阵,Hermes Agent 是类似的助理工具。我当时对比了两者之后,毫不犹豫选择了 Hermes,此后再没用过 OpenClaw。Hermes 的配置和交互更人性化,支持自学习和持久记忆,也兼容多种 IM 工具和 TUI,迭代节奏一直很快。
让我印象最深的一点是:Hermes 会把完成过的工作沉淀成 skill,下次遇到类似任务时主动复用。用起来更像一个积极主动的团队成员,而不只是一个工具。
桌面版出现之前,Hermes 的门槛在哪里
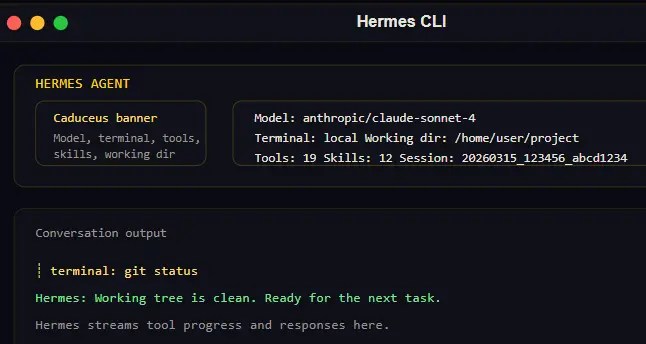
在桌面版推出之前,Hermes Agent 和小龙虾一样,本质上还是一个给技术用户准备的工具。用户至少要对 CLI、TUI 有基础,才能开始配置。配置文件、provider、API key、gateway、toolset、MCP、dashboard,每一项都是单独的门槛。对喜欢折腾的人来说,这些是高自由度;对普通用户来说,根本不知道从哪里下手。
因此,大多数只熟悉图形界面、习惯点击「下一步」的用户,基本上是无缘这类工具的。
不是另一个聊天客户端
理解 Hermes Desktop,首先要避开一个误区:它不是独立做了一个 ChatGPT 或 Codex 的替代品。
Hermes Desktop 用的是同一个 Hermes Agent core。CLI、TUI、Gateway、Desktop 不是几套割裂的系统,而是同一个 Agent 的不同入口。它们共享配置、API key、session、skill、memory。你可以在命令行里开启一个任务,再到桌面版继续查看;也可以在桌面版配置模型、管理 skill,再回到其他入口继续用。
严格来说,Hermes Desktop 是一个 agent 客户端,更接近 Codex 而不是 ChatGPT。Agent 会执行一系列动作,在获得授权后控制浏览器或文件系统,最终达成用户目标。对话 chatbot 只是 agent 的一个子集。
桌面版降低的是操作成本
虽然 Hermes Desktop 的主界面依然以会话为中心,但它不只是给你一个输入框加一串回答。
左侧导航用于管理多个 agent 会话,中间是对话区,可以看到 streaming response 和工具调用过程,右侧有 preview rail,可以并排查看网页、文件和工具输出。同时内置文件浏览器,让你不用离开 App 就能看到 agent 正在读写哪些项目文件。
这类设计看似普通,但对 AI Agent 非常关键。Agent 和普通聊天机器人的差别,正是它会「做事」——读文件、写文件、搜索网页、执行脚本、调用工具。如果这些动作全部藏在黑箱里,用户很难建立信任;如果每一步都要去看终端日志,普通用户又受不了。桌面版把 agent 的工作过程可视化,降低的正是这部分操作成本。

设置终于不再全靠 YAML 和命令行
我一直觉得,AI Agent 工具要进入日常工作流,最大的门槛不是模型能力,而是配置体验。
选 provider、配置模型、决定启用哪些工具、管理 API key、连接 MCP server、设置 gateway——如果这些全部散落在命令行参数和配置文件里,用户很快就会放弃。
Hermes Desktop 这次把这些配置都放进了 UI:provider、model、tools、credentials、MCP servers、gateway、session management,都可以在桌面端直接管理。
当然,这并不代表它变成了「下载就能无脑使用」的产品。复杂的配置仍然需要一定的专业背景,必要时还是得手动处理配置文件和命令行——毕竟它们本来就是一体的。但至少门槛从「必须会命令行」降到了「理解系统基本结构即可」。这已经是很大的变化。
Windows 用户也被照顾到了
这是我很在意的一点。
很多开源 AI Agent 项目,名义上支持跨平台,实际上主要面向 Linux / macOS,Windows 用户不是被要求装 WSL,就是在各种依赖里折腾半天。
我在 Windows 10 上测试了 Hermes Desktop 的原生支持:不需要 WSL、Cygwin 或 Docker,安装器会自动处理 Python、Node.js、PortableGit、ripgrep、ffmpeg 等依赖,放在用户目录下,不需要管理员权限。整体体验和 macOS 下几乎一致。
一个 AI agent 工具,如果只在 Linux 服务器上体验好,它更像是服务器基础设施;如果能在 Windows 和 macOS 桌面上跑起来,它才有机会成为个人工作流的一部分。Windows 和 macOS 互为竞争对手,是对用户最好的状态。一个 agent app 只有覆盖两边,才算完整。

我真正感兴趣的是持久记忆和 skill
现在很多 AI 产品都在讲 agent,但大多数实际还是一次性对话:给一个任务,做一次,做完结束。下次还要重新解释背景、偏好和注意事项。
Hermes Agent 更有意思的地方,是它强调 persistent memory 和自动生成的 skill。它不只是记住聊天记录,而是把解决问题的方法沉淀成可复用的 skill。
从生产力工具的角度看,这个方向比「一次性更聪明」重要得多。真实工作里,很多任务不是全新的,而是反复出现的——整理某类资料、生成某类报告、检查某类文件、定期做研究、把信息推送到某个渠道。如果 agent 每次都重新理解一遍,本质上还是高级聊天;如果它能把流程固化下来,下次自动套用,它才开始接近一个工作系统。
Hermes Desktop 把 skill、cron、profile、messaging、agents 和 command center 这些管理入口放进桌面端,本质上是把「长期运行的 AI 工作系统」搬到了用户更容易触达的位置。
我在 AI 普及之前就有这样的认识:真正的效率来自归纳。一类事情做多了,会形成工作流;工作流用多了,会沉淀成自动化工具。用现在的视角来看,这就是 agent 的 skill 迭代逻辑。
适合谁用
先泼一点冷水:Hermes Desktop 目前不是面向完全零基础用户的产品。
技术门槛之外,更主要的问题是它的能力边界太宽。Hermes 可以连接不同模型,调用工具,读写文件,跑浏览器自动化,执行定时任务,接 messaging gateway,连接远程 backend……
如果日常事务还没有复杂到需要 AI 介入,或者完全不想归纳自己的工作流,目前的 agent 工具帮不了太多。
我觉得 Hermes Desktop 目前最适合三类人。
第一类,已经在用 Claude Code、Codex、Cursor、OpenHands、OpenWebUI、n8n、MCP 工具的人。他们理解 AI 工具调用和自动化的价值,只是需要一个更完整的 agent 工作台。
第二类,研究型创作者、技术写作者、独立顾问、产品研究人员。他们经常需要收集资料、阅读网页、整理文件、生成报告、沉淀流程。Hermes 的 memory、skill、定时任务和多入口交互,可能会逐渐成为一套长期积累的个人研究助理。
第三类,有自部署习惯的人。比如愿意在本地机器、家用服务器、VPS 或 Tailscale 网络里跑自己工具的人,希望数据和流程尽量掌握在自己手里。Hermes 的整体方向和这类用户的偏好比较契合。
如果你只是想找一个简单的问答工具,ChatGPT、豆包、千问这类会更直接。
最后
Hermes Desktop 的发布,在某种意义上标志着开源 AI Agent 正在进入下一个阶段。
第一阶段是命令行和开发者工具,大家关心的是能不能跑、能不能调工具、能不能自动执行任务,它更像是 AI 基础设施。
第二阶段是桌面工作台,大家关心的是能不能看清楚它在做什么,能不能管理多个任务,能不能控制权限,能不能把经验沉淀下来,能不能长期陪伴一个项目。这才是逐渐面向最终用户的接口。
Hermes Desktop 目前仍然有些粗糙,也仍然需要用户理解不少 AI Agent 基础概念。但未来已经在地平线上浮现——下一个操作系统、下一个 Office、下一个浏览器,这种量级的应用框架已经有了雏形。无论最终是不是 Hermes,这个方向都值得认真关注。
-
【译】我在 OmniFocus 中待了九年。然后我改用文本文件来管理。

写在前面
在 GTD 风潮兴起的时期,OmniFocus 曾经是任务管理 App 中的一代经典。
直到今天,OmniFocus 仍有大量粉丝。毫不夸张地讲,它影响了后来很多 todo 类工具,甚至在苹果自带的「提醒事项」里,也能看到 OmniFocus 的影子,比如后文会讲到的「透视图」。
我个人从 OmniFocus 2 开始入坑,但现在已经退烧很久了。我很想讲讲自己为什么退烧,但又很难归纳。最近,我看到一篇文章,讲述作者如何从 OmniFocus 切换到纯文本任务管理,我觉得和自己的经历有不少相似之处。因此,特别想分享给大家。
在分享之前,我要提醒一下:下面的文章对于一些读者来说,可能比较生涩。我已经尽力简化和注释了。我觉得文章的理念比较重要,大家不要纠结于里面的具体代码。即使完全不会代码,也有大量第三方工具可以实现类似的功能。
大家会看到 Obsidian、Logseq 的影子。如果看到 Denote 那部分,是不是也会对「文件名标签」唤起一丝熟悉感?而纯文本对同步的友好性,以及对 AI 工具的加成,例如 Claude Code、Codex,也会是未来的重要方向。这一切,都是效率火箭这些年来反复提到的东西。
最后再啰嗦一句,每个人的情况都不太一样。OmniFocus 之类的 todo 工具仍旧有用武之地,只是一部分作用被分流出去了。原作者恰好是一名后端工程师,那么绝大多数工作任务都可以被更「接地气」的方式分流出去,并不是说每个人都要做相同的实践。
我个人也仍旧保留了 todo 工具,但显然也注意到,大量具体工作任务已经被分流到了具体的项目文件夹里,并且开始和 AI 进行协作。可能这也是 OmniFocus 这类重度 todo 工具逐渐退出我视线的原因之一。
原作者:Max Holovanov
原文链接:https://medium.com/@maxclax/i-spent-9-years-in-omnifocus-then-i-switched-to-a-text-file-4190628ed11f
火箭君整理、编辑、翻译。以下正文。正文
我觉得,OmniFocus 是花钱能买到的最好任务管理器。我用了九年,然而现在我转向了「纯文本」。
与 OmniFocus 共事的九年
我大约在 2011 年开始使用 OmniFocus。
九年来,它管理着我的生活,直到 2020 年,我把一切迁到了 org-mode。我想一开始就说清楚:它是一款出色的软件。如果今天有人问我「花钱能买到的最佳任务管理器是什么」,我仍会毫不犹豫地说是 OmniFocus。
它把重要的东西做得恰到好处。收件箱捕捉是瞬时的。项目模型可靠。推迟日期、回顾周期、视角,整个 GTD 机制都在,而且打磨得光亮如新。移动端应用也确实出色:可以随时随地捕捉想法,也可以在火车上回顾任务,或站在商店里查看某个情境。多年来,那恰恰是我生活所需的视图,它实现了这一点。我通过它推进的每一个项目都达成了结果,没有任何事情被遗漏。
这是一个故事:一个曾经非常有用的工具,如何因为「用户摩擦」而逐渐退出我的工作流。
没人提起的「摩擦」
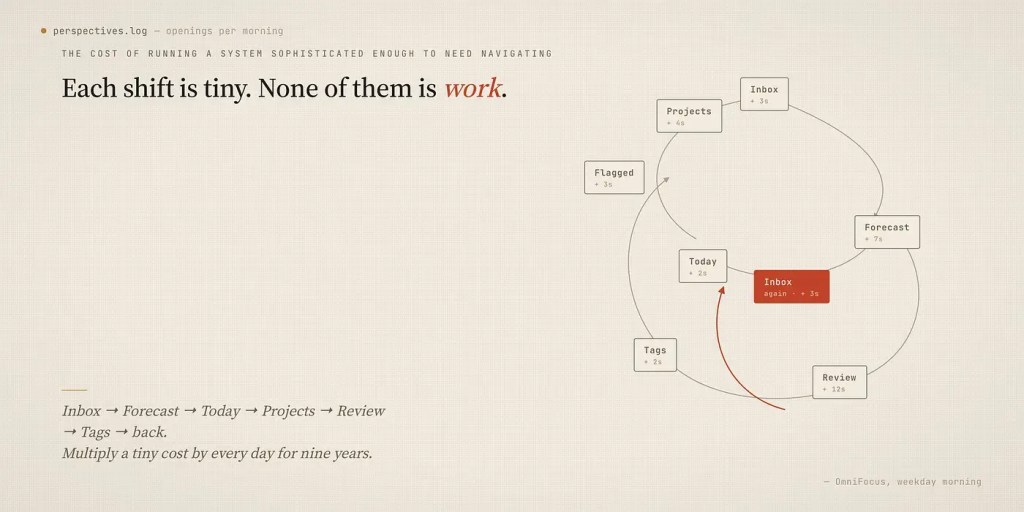
以下是我在日复一日使用 OmniFocus 时开始感受到的问题:我花在视图切换上的时间出乎意料地多。
OmniFocus 是围绕透视视图构建的。透视视图本质上是保存好的筛选器,可以按情境、项目、标签、可用性来划分任务。透视视图很强大。但功能强大,也意味着透视视图很容易越建越多。
我会打开应用,然后开始来回切换:收件箱,然后是预测视图,然后是一个自定义透视视图,然后是项目,再切回。每次切换都很微小。它们都不是实际工作,而是工作的管理,是运行一个复杂到需要导航的系统所付出的代价。
把每天一个微小的代价乘以多年,它就不再微小。
我一直在反复思考一个挥之不去的问题:如果系统可以变得更简单会怎样?不是能力降低,而是更简单。如果我的任务更贴近实际工作所在,而我不必特意去「导航」到它们那里,会怎样?
为什么选择 Org-mode
我在其他一切事情上已经生活在 Emacs 里。Org-mode 就在那里,优势显而易见:任务就是
.org文件中的纯文本。没有数据库,没有同步引擎,没有专有格式。任务就是一行。项目就是一个文件。议程是对那些文件的一次查询。诚实地说,Org-mode 真正阻碍我的问题是「移动端」。OmniFocus 的手机应用是我九年来一直依赖的东西,我不想放弃人在办公桌以外的任务捕捉和回顾能力。
现在,BeOrg 这款 App 完全解决了这个问题。这是一个 iOS 应用,可以直接从 iCloud 或 Dropbox 读取和写入纯 Org 文件。在手机上捕捉到收件箱、勾掉 TODO、浏览议程,离线也可用,并且会以纯文本同步回去。只要我确认移动端捕捉仍然可行,留下来的最后一个理由就消失了。
桌面端的捕捉保持刻意简单,甚至有些无趣。一个收件箱文件,一个模板:
(setq org-default-notes-file(expand-file-name "inbox.org" org-directory))(setq org-capture-templates'(("t" "Quick todo → inbox" entry(file org-default-notes-file)"* TODO %?")))用快捷键输入想法,完成。从手机上的 BeOrg 应用也会追加到同一个
inbox.org。一个收件箱,两台设备,零转换。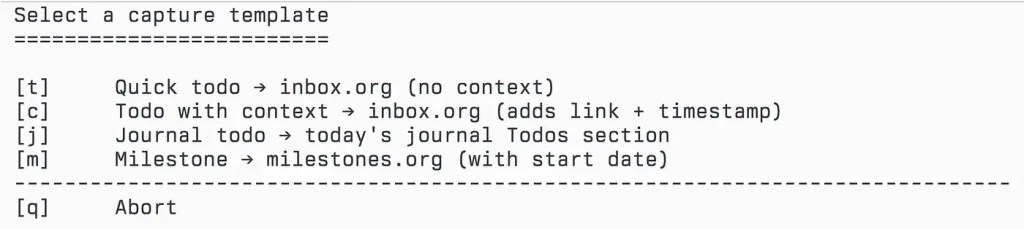
真正的原因:任务就在工作发生的地方
移动端曾是阻碍。但那并不是根本原因。真正的原因是:
当我在处理一个项目时,我已经在它的目录和文件中。使用 Org-mode,我可以直接在上下文中写下任务,不需要切换应用,也不需要在一个单独的工具中重新查找项目。每个项目都有自己的路线图文件
ROADMAP.org,所谓的 Agenda(议程视图)则简单地将它们全部收集起来。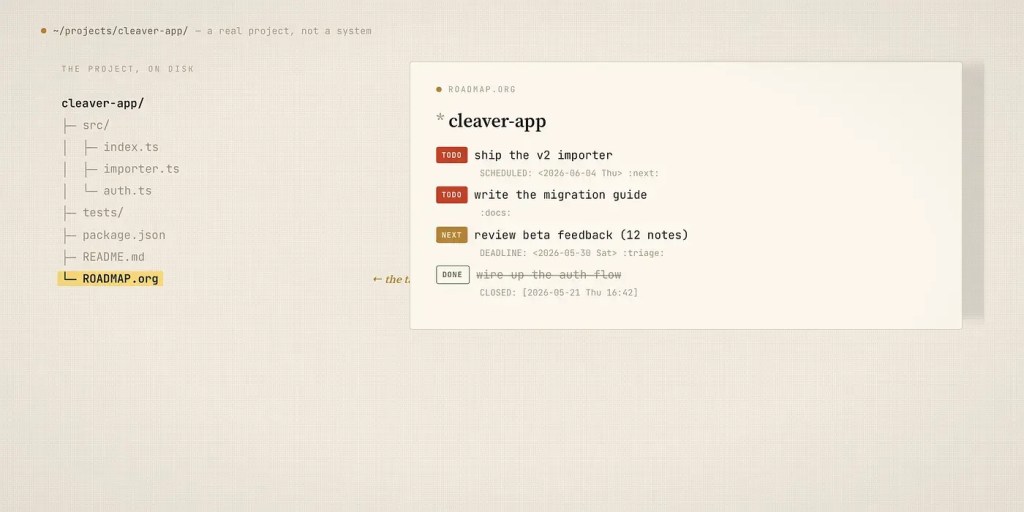
这是 OmniFocus 透视视图从未给过我的东西。任务不再驻留在一个我必须专门去访问的工具里。它就位于我正在执行的工作旁边,议程只是负责把它们汇总出来。
这一单一改变,几乎一次性消除了所有视图切换的摩擦。再也没有「打开任务管理器」这一步了。任务管理器就是我已经在编辑的那些文件。
我重新调整了流程,因为议程扫描会蔓延
我的第一个本能,是把
ROADMAP.org文件直接散布在每个代码仓库里。感觉很纯粹:路线图就和工作文件、源码并排而居。后来事实证明,这是个错误,Emacs 很快就让我意识到了这一点。每次启动都变得更慢。
一旦你看到原因,它其实很简单。Org 的议程通过扫描目录来构建文件列表。如果你把它指向包含代码项目的目录树,它会递归进入
node_modules、.git、build/、vendor/,成千上万的文件在每次议程构建时都要走一遍。要么你永远维护一份小心翼翼的排除列表,要么你接受慢启动。这两者都意味着系统开始要求你管理系统本身,而这正是我想要逃离的东西。于是结构演进了。我没有再把路线图文件散落在各个代码仓库里,而是迁移到一个单一、专用的笔记目录,并为每个项目创建一条自己的 Denote 注记。
Denote 是一个极简的笔记包:每个文件都有一个带时间戳和关键词标签的名称,基本上这就是全部理念。设置很简单:
(use-package! denote:config(setq denote-directory "~/org")(setq denote-file-type 'org);; Lifecycle keywords — project / area / resource / archive(setq denote-known-keywords'("project" "area" "resource" "archive""reference" "meeting" "idea" "someday")))火箭君注:Denote 是一个文本笔记,但是 文件名上包含标签和时间戳之类的「元信息」,这样系统就可以根据预定义规则,按照标签等条件筛选内容展示。
每个项目就是一条 Denote 笔记,标记为
project,并具有一个可预测的内部结构:目标、下一步动作、未来某天。议程只扫描这一目录,而这个目录也只包含笔记。没有需要排除的东西,因为这个目录附近根本没有node_modules:;; Skip dotfiles; only ever scan the notes directory — never code repos(setq org-agenda-file-regexp "\\`[^.].*\\.org\\'")(setq org-agenda-files(seq-filter(lambda (f) (not (string-match-p "/templates/" f)))(directory-files-recursively "~/org" "\\.org$")))是的,我放弃了「任务就在源文件旁边」那种纯粹性。换来的回报是,一个启动即用、永远不需要调校的系统。这个权衡显然是正确的。Denote 最终让整件事呈现出来的是简单,而不只是纯文本。
关于同步:别想太多
有一段时间,我用 Syncthing 来同步一切。它能用,而且如果设备从不接触商业云服务,它仍然是个相当不错的选择。
但对于纯粹的 Org 文件来说,说实话,这有点大材小用。Org 模式下,信息只是一些小小的纯文本文件而已。没有什么数据库会损坏,没有复杂的数据结构,也不需要合并引擎。所以我让显而易见的工具做显而易见的事情:笔记目录放在 iCloud Drive 上。BeOrg 在我手机上读取同一个 iCloud 文件夹。当然,Google Drive 同样可以胜任。
纯文本才是这里的特点。任何同步方式都行,因为没有什么需要智能同步。它只是单纯的文件而已。
我没料到的回报:AI 时代的纯文本优势
当我在 2020 年切换时,我根本没在考虑人工智能。事实证明,它比这份清单上的其他任何东西都更重要。
Org-mode 不会删除已完成的工作,它会把它归档。在一个已完成的任务上按下一组快捷键,整个子树就会移动到一个归档文件:标题、
CLOSED时间戳、优先级、标签,以及你一路上添加的所有笔记。;; Completed tasks move to a dated archive, not the void(setq org-archive-location "~/org/archive/%s_archive::")想想那个归档实际上是什么。Git 历史记录告诉你代码发生了什么变化。你的 Org 归档告诉你,你决定做什么、为什么要做,以及它已经完成。这些都用你自己的话记录了意图和结果。这是一种不同的、在某些方面更丰富的日志:项目的记忆,而不仅仅是差异。
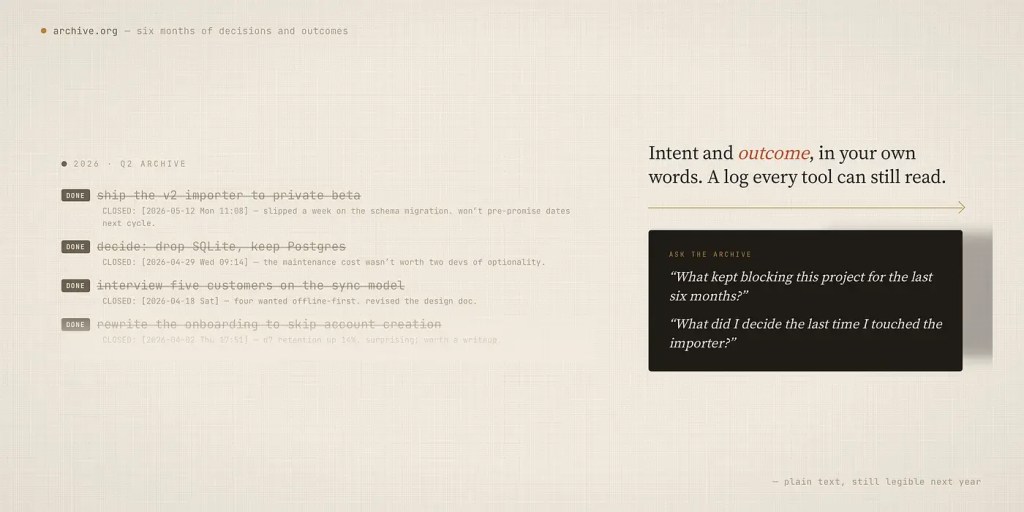
而且因为它是纯文本,人工智能可以读取所有内容。我可以把六个月的归档任务交给模型,并提出真实的问题:是什么一直阻碍了这个项目?时间到底都花在哪儿了?我上次接触这个东西时都说了什么?归档不再是坟场,而是一个输入。项目的每一个新阶段,都可以以它自身的历史作为上下文,既为我提供参考,也为模型提供参考。
专有的任务数据库做不到这一点。它的历史被锁在只有供应商应用才能理解的格式里。纯文本对所有工具都保持可读,包括那些在你写下这些内容时还不存在的工具。这就是纯文本在长期里悄然胜出的理由:你不是在为当下的应用选择格式,而是在为明年的工具仍能读取的格式做选择。
Org-mode 负责运行任务,我仍然手工规划结果
到这里,如果用「现在一切都在 Org-mode 里」来给本文作结,会显得优雅整洁。但那并不真实。
Org-mode 运行我所有的任务和整个日程,包括捕获、项目、截止日期、每日回顾。那是执行层,而且完全数字化。但高于任务的那一层,也就是决定一个季度走向的少数几件事,我仍然手工规划。
为此,我为 Kindle Scribe 自己制作的一个计划本,因为在四月之前,市面上的七个现成计划本都没能满足我。
每天三件成果,每周三件,每月三件,每年三件。这个限制「三」就是重点。
「三」会迫使我做出真正的选择,而不是列一张愿望清单。并且成果要写成已经完成后的状态:不是「完成报告」,而是「我完成了报告,现在我可以……」。这会把注意力拉到影响上,而不是动作本身。
为什么把那部分保留为纸质?因为任务和成果需要不同的仪式。任务需要快速、可查询、可自动化,这正好是 Org-mode 的风格。成果则需要慢下来。我用电子墨水手写,没有通知,也没有可点按的东西。这种摩擦反而是有益的:它让我在 Org-mode 把一周填满动作之前,先静下来思考什么是真正重要的。
所以真正的系统是两层的。决策目标用手写,决定三项成果。Org-mode 以数字形式,执行所有属于这些成果的任务。纯文本并没有取代纸张,它解放了纸张,让纸张去做它仍然最擅长的那一件事。
这一切值得吗?
诚实地说,总有取舍。
OmniFocus 更加精致。它的移动端、复习模式、推迟和预览体验,所有这些都确实比我搭建的任何东西好。如果你想要一个安装当天就能完美运行的系统,就买 OmniFocus,别再往下看了。
Org-mode 是一个项目,而不是一次购买。我花了真金白银的时间去让捕捉、议程和 Denote 协同工作。你在读这篇文章,是为了跳过其中的一些步骤,但不可能全部跳过。
前提是,工作流里本来就需要 Emacs。我并不是为了任务采用 Emacs;我本来就长期生活在 Emacs 里。如果各位没有这种需求,情况就完全不同。
火箭君注:即使大家不是代码开发者,比如作者,比如分析师,比如咨询业,只要工作围绕着数字文件展开,其实仍旧可以基于项目文件夹工作,就像我一样,因此这个思路一样成立。这也是 Obsidian 之类工具兴起的原因之一。
我获得的是:我的任务不再是我偶尔访问的地方。它们和我的工作并列,以纯文本文件存在,由议程统一查询,再通过一个文件夹完成同步。那种视图切换的成本,每天一点点,持续九年,终于消失了。
OmniFocus 并没有输。我只是想要更少的系统,而纯文本是唯一能给我这种感觉的方式。
补充
原作者的完整 Org 和 Denote 配置:
https://github.com/maxclax/dotfiles
BeOrg 官网:
-
对于不得不使用 Windows 的生产力用户来说, 一定要装上 最新的 PowerToy,它原本就应该集成在 Windows 里面

写在前面
我不想争论是 Windows 系统优秀,还是 macOS,还是 Linux。三者各有千秋,而且不少地方也有逐渐趋同的样子。一定要概括一下三者的优劣,我大概会这么说:
macOS:更好的使用体验,绝大多数消费级软件(除了游戏)的支持,苹果生态的加成,但也有较狭隘的硬件选择范围,和较高的苹果税。macOS 面向消费者更多些,而且用户体验相对出色。
Windows:有很多习惯上和历史上的积累,更好的外设驱动,更多的硬件选择,预算可以从简朴到奢华,也有不少可折腾的地方;但是原生功能和体验经常让人无语。很多时候我甚至觉得,Windows 应该放弃桌面,只保留运行时,其它东西索性交给第三方算了。Windows 面向工作者更多些。
Linux:很适合折腾,但对于消费级用户和传统意义上的生产力用户,实在不算友好。如果只是学习和测试,Windows WSL、macOS 终端都有很不错的替代性。考虑到 Linux 是大量网络,移动设备和云端系统的基础操作之一, Linux 面向开发者更多些。
我们还是说回 Windows。Windows 不是那种特别适合伴随我们生活的系统,但是工作上可能会非常需要,尤其是追求结果而不是过程的那种工作。

问题在于,Windows 自带的很多功能都缺乏考虑。即使对专业用户来说,也经常有掣肘。
所以,我今天想说的就是 PowerToys,一整套为 power user 准备的 Windows 实用工具。它可以改善 Windows 缺失的那些功能,如标题所说,其中很多功能,原本就应该集成在 Windows 里面。
新版 PowerToys 登场

截至目前,PowerToys 最新稳定版是 v0.99系列,真正值得关注的新功能包括 Power Display、Grab And Move,以及 Command Palette、Dock、Keyboard Manager、ZoomIt 等工具的改进。
PowerToys 出自 Microsoft 自己,是一套免费、开源的 Windows 工具集合。微软是一个很奇怪的组织,里面山头林立,有些部门的产品就让人很伤脑筋,而有些部门的产品就很优秀,比如: WSL,Powershell 这种就很优秀, 也许普通用户注意不到,但生产力用户就很受用。
PowerToys 的定位是:帮助 power users 和开发者更好地使用 Windows,补足一些系统本身没有提供,或者提供得不够顺手的能力。呵呵,像是一个部门对另一个部门的补丁。
早年的 PowerToys 只是零星几个小工具,后来逐渐壮大,变成了一个包罗万象的工具箱。现在它已经不是简单的「高级用户玩具」,而是很多 Windows 用户都可以直接受益的生产力补丁。
它主要包括几类工具:
- 第一类是窗口和桌面管理,比如 FancyZones、Always On Top、Grab And Move、Workspaces。
- 第二类是文件处理,比如 PowerRename、Image Resizer、Peek、File Explorer add-ons、File Locksmith。
- 第三类是输入和快捷操作,比如 Keyboard Manager、PowerToys Run、Command Palette、Quick Accent、Advanced Paste。
- 第四类是屏幕工具,比如 Color Picker、Screen Ruler、Text Extractor、ZoomIt、Mouse utilities。
- 第五类是系统增强,比如 Awake、Hosts File Editor、Environment Variables、Registry Preview、Mouse Without Borders。
微软官方文档目前列出的可用工具已经超过 25 个。
这套工具最有意思的地方在于,它不是一个巨大的软件,而是一组可以单独开关的小工具,加上一个中心控制面板。小工具我们不需要全用,也不需要被迫接受某种工作流。只要根据需要开启对应的小工具选项即可。
这次比较有特色的新增功能:Power Display
新版 PowerToys 里,我最先注意到的是 Power Display。
这个功能解决的是一个很具体、但很多桌面用户都会遇到的问题:外接显示器太难调了。
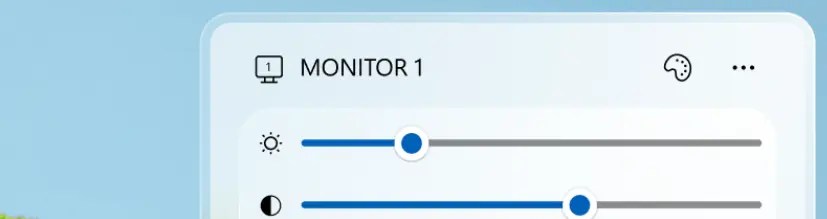
很多显示器的实体按键都藏在背后,菜单逻辑也很别扭。调个亮度、对比度、输入源,像是在和显示器斗智斗勇。尤其是多显示器用户,或者一台显示器接多台设备的人,调整显示器设置一直是一件小但烦的事情。
Power Display 的思路很直接:把显示器控制放到 Windows 系统托盘里。启用之后,它会自动检测连接的显示器。如果显示器支持相应控制能力,就可以直接调整亮度、对比度、音量、输入源、色彩配置等内容。它还支持创建 profiles,也就是显示器配置预设,方便一键切换不同场景。
这类功能本来就应该是系统级能力。笔记本内屏可以调亮度,外接显示器却经常要靠显示器背后的按钮,这件事终于有解决了。
Grab And Move:移动窗口终于不用瞄准标题栏
另一个新增功能是 Grab And Move。 我个人超级喜欢。
它的作用非常简单:默认按住 Alt,然后在窗口任意位置左键拖动,就能移动窗口;按住 Alt 右键拖动,就能调整窗口大小。如果 Alt 和你的使用习惯冲突,也可以换成 Win 键(我就换成了 Win 键)。
这听起来像是一个小功能,但用过类似桌面环境的人应该知道,它会明显减少窗口管理里的摩擦。
Windows 里很多窗口边缘很窄,标题栏又经常被各种自定义界面改掉。特别是在大屏、多屏、远程桌面、高分辨率屏幕上,移动和调整窗口并不总是舒服。Grab And Move 让你不需要去找标题栏,也不需要精准对准边缘,只要鼠标在窗口里面,就能完成操作。
Command Palette 和 Dock:Windows 本该有一个命令入口
PowerToys 以前最受欢迎的功能之一是 PowerToys Run,一个类似启动器的工具。现在 Microsoft 明显在推动 Command Palette,把它变成更统一的命令入口。 根据我以前的印象, PowerToys Run 似乎和 Wox 这款知名的 Windows 启动器有一定的渊源。
Command Palette 不只是打开 App,还可以访问命令、工具、扩展、计算器、Terminal profiles 等。新版里,Command Palette 和 Dock 有很多改进,包括 Compact Dock、始终置顶、计算器历史、命令固定方式优化,以及扩展内容显示能力增强。
Windows 的入口一直太分散。开始菜单、搜索框、任务栏、系统托盘、右键菜单、快捷键、设置页,各管各的。Command Palette 的意义不是替代所有入口,而是给重度用户一个更快、更统一的操作中心。 这是 Windows 应该自带的,就像 macOS 的 Spotlight,结果 Widnows11 原生给了一个不知什么东西糊的开始菜单。
如果我们每天反复打开固定工具、运行固定命令、切换 Terminal 环境,Command Palette 就会比开始菜单更像一个真正的工作台。
我个人比较喜欢的几个老功能
如果你第一次装 PowerToys,我不建议一口气把所有功能打开。我个人比较喜欢的几个老功能是 FancyZones、Peek、PowerRename、Image Resizer。
FancyZones 是窗口分区工具。Windows 自带分屏已经比以前好很多,但还是不够自由。FancyZones 可以自己画窗口布局,把软件拖进去自动吸附。对 27 寸以上显示器、超宽屏、多屏用户来说,这个功能很值得开。
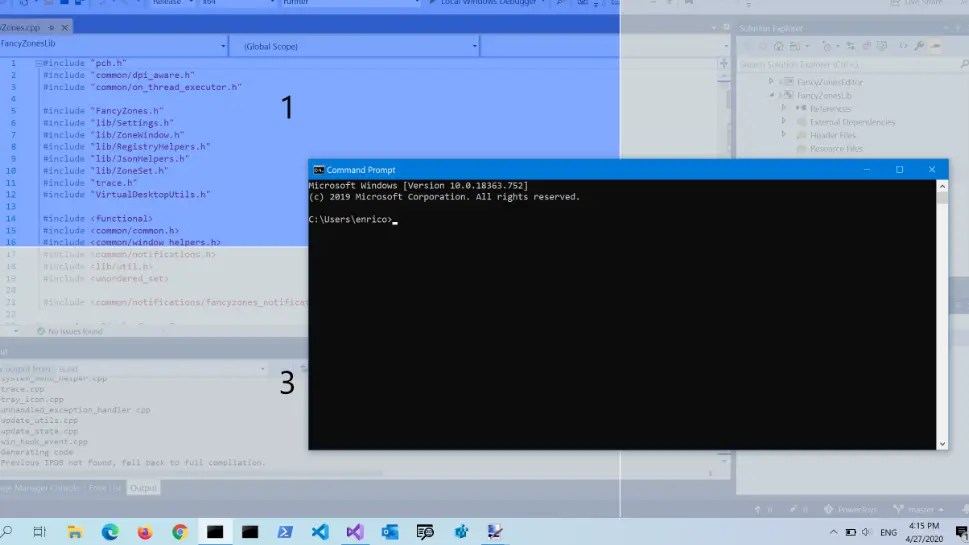
Peek 是快速预览文件。选中文件后,不用打开完整应用,就能看内容。图片、PDF、Markdown、代码文件、文本文件都很适合这种方式。它有点像 macOS 里的快速查看,但放在 Windows 里就显得格外必要。
PowerRename 用来批量改名。替换文件名、正则匹配、撤销操作,这些功能如果没有专门工具,靠 Windows 原生资源管理器会很痛苦。
Image Resizer 则适合经常处理图片的人。右键就能批量调整尺寸,不用每次打开图片编辑软件。写博客、发图、整理截图时很省事。
一些比较小众的工具
下面这些,也许不是人人需要,但我有时或之前会用到。
Always On Top,可以快速将一个窗口 始终钉在最前面,就像固定桌面便签那种。 我发现还是有些 bug 的,不是所有窗口有效。
Keyboard Manager,这个工具可以重映射按键和快捷键,比如把不常用的按键改成更顺手的组合。实际上,我后来都是用 AHK 替代。
如果你经常临时需要电脑不要休眠,比如下载文件、跑任务、开会投屏,可以开 Awake。它的好处是不用改系统电源计划,用完关掉即可,类似 macOS 下的 Amphetamine 这类工具。
Advanced Paste,它可以把剪贴板内容转换成你需要的格式,也包含可选的 AI 能力。但我不推荐使用,因为剪贴板工具很多,而且剪贴板内容很敏感,经常会有账户密码之类的信息。
最后
PowerToys 最有价值的地方,不是它有多酷,而是它真的在补 Windows 的日常短,PowerToys 是 Windows 最应该内置的补丁包。
如果我们现在还在用 Windows,而且每天都要在文件、窗口、截图、文本、显示器之间来回切换,PowerToys 值得安装一次。也不要功能全开,只挑真的会用的那几个工具打开使用即可。
PowerToys 不会把 Windows 变成 macOS,也不会把桌面系统变成什么理想形态。它只是让 Windows 多一点顺手,让我们将更多精力投入专注工作,这就够了。
PowerToys 官网地址
-
2026 年,小而美 Markdown 编辑器,正在变成 AI Agent 的本地工作台
很久以前,Markdown 编辑器曾经很热闹
很长一段时间里,Markdown 编辑器这个品类似乎已经没有太多新故事了。
以前那些主打优雅写作体验的 Markdown 编辑器,很多早已淡出视野。有不少是 macOS 独占的,还有一些众筹之后因为交付和沟通问题引发争议的案例……现在回头看,很难想象一个 Markdown 编辑器在当年也能搞众筹。
如果现在只是写一篇文章,Typora 已经足够顺手。很久以前,每当我有新设备,总是会安装付费版的 Typora;后来转向了免费的 MarkText,也很出色,Typora 现在已经几乎消失在我的视野里了。

再后来,主角基本变成了笔记库。Obsidian 的崛起,已经带来了完整生态;如果要处理代码和相关文档,VS Code 也完全能胜任。于是很多人会觉得,新的 Markdown 工具是不是已经没有机会了?
但我最近连续看了一批新的 Markdown 工具之后,尤其是结合上次介绍的 Tolaria,我感觉有一个变化正在发生:新一代小而美 Markdown 编辑器,已经不只是为了「写 Markdown」而生,而是开始变成 AI Agent 可以直接接管的本地文本工作台。
也就是说,文件仍然是
.md,仍然在你的磁盘上,仍然可以用 Git、Syncthing、iCloud、Dropbox 或任何文件同步方式处理。编辑器旁边多了一层新能力:AI 可以搜索、总结、改写、整理、生成任务,甚至通过 MCP 直接读写同一个 vault。这和许多把内容上传到云端再调用 AI 进行加工的笔记产品,是两种完全不同的路线。
不要再只把它们看成 Typora 替代品
下面这几款新兴工具,如果按老眼光看,很容易被理解成「又一个 Typora」,但实际上并非如此。
Clearly 的定位很克制:打开一个
.md文件,写作,语法高亮,切换预览。它是 Mac 和 iPhone 原生应用,官网也直接写着 free and open source。我个人试了一下,的确很清爽,是 macOS 下的理想选择之一。(下图)
Cogito 则更接近「文件夹优先」的 Mac 原生笔记工具。它可以添加本地文件夹,支持
[[Wiki links]]、Obsidian 风格 embeds、任务勾选、PDF 导出,还内置 AI Chat,用来编辑和 review 文件。你也可以把它理解成一个更轻量级的 Obsidian。writer.computer 走的是另一条更加工程化的路。它基于 Tauri v2、React、CodeMirror 和 Rust,文档保存在磁盘上,尊重 workspace 的
.gitignore,支持多窗口,也能渲染表格和 Mermaid。速度快,整体是很务实的工程化风格。值得一提的是 Quarkdown。 这是另一个很有意思的产品。它不是普通编辑器,而是 Markdown-based typesetting system,可以通过
.doctype输出 papers、presentations、knowledge bases、static websites 等形态,并支持脚本化复用内容。如果想用 Markdown 生成更复杂、更正式的排版文档,Quarkdown 是个不错的发展方向。 (下图)
这些可以算是传统 Markdown 编辑器的升级版或后继者,但真正有意思的是另一批工具。
Markdown 开始变成 Agent 的操作界面
VMark、ZenNotes、SoloMD 这几款,已经不是简单地比谁的预览更漂亮,谁的主题更多。它们真正争夺的是:AI Agent 能不能安全、直接、可控地操作你的本地文本资料。之前介绍过的 Tolaria,也可以放在这个流派里。
VMark 自称它不只是 Markdown,而是一个 plain-text workspace,支持 Markdown、YAML、JSON、TOML、Mermaid、SVG、HTML、Code,并且通过 MCP 让 Claude、Codex、Gemini 直接读写同一批 artifact。
ZenNotes 的方向也很清楚:键盘优先、本地 Markdown vault、内置 MCP server、
zenCLI,并支持 Claude Code、Claude Desktop 和 Codex 直接编辑同一批磁盘上的 Markdown 文件。它还支持 Mac、Windows、Linux 桌面端,以及自部署 Web App。(下图)
SoloMD 野心很大,似乎想把自己做成一个包罗万象的 Markdown editor,同时也是连接 LLM 的桥。它强调 local-first、Git 分支管理、RAG embeddings、密码存储保护,当然也内置 MCP server,可以让 Claude Code、Codex、Cursor 直接驱动你的 vault;同时支持多个 BYOK AI 服务商。但我个人觉得它有点复杂,试用之后,不太有继续使用的动力。我更喜欢 Tolaria 那种风格。
几款工具如何选择
如果只是单篇 Markdown 文件编辑和管理,我不会把问题复杂化。Clearly 足够轻,Cogito 和 Writer 的使用体验也很舒服。现在正在用的 MarkText 也很不错。但至少对我来说,Typora 已经不会再作为首选了,时代确实变了。
如果你要做正式文档或长期笔记管理,Obsidian 仍旧是首选。想要接入 AI,Obsidian + Claude Code、Codex、OpenCode 等等,我之前有介绍,仍旧是不错的实践方式。
如果你关心前沿的 AI Agent 工作流,喜欢 All-in-one,那么前面提到的 VMark、ZenNotes、SoloMD、Tolaria,都是值得一看的产品。
Markdown 编辑器层出不穷,但 Markdown 本身并不是一种过时格式,而是成为了 AI 时代最容易被人和机器共同理解的本地数据层。
其它候选工具
Moraya:Tauri + WYSIWYG + AI Agent,方向和 SoloMD 接近,但还需要观察成熟度。
Otterly:像是更加轻量的 Obsidian / Cogito 路线,本地 vault 是重点。
Marko:Tauri、文件夹、Wiki links、Git,朴素但实用。
Inkwell:便携、离线、无账号,适合只想打开文件写作的人。
MerMark Editor:适合 Markdown + Mermaid 技术文档场景。
Nimbalyst:不算纯 Markdown 编辑器,更像 Claude Code / Codex 的可视化工作台,但代表了 Agent workspace 的趋势。
MarkEdit:不算新兴,但依然是 Mac 上小而美 Markdown 编辑器的稳定样本(下图)。
最后
我以前看 Markdown 工具,主要看:写作体验、预览效果、导出能力。
现在,基础功能早已被反复实现,「重新造的轮子」都可以绕地球几圈了。尤其是 AI Coding 使得各种廉价工具层出不穷,它们多半会被遗弃,但总会有精华保留下来。我会观察它们能否长期留下来的几个方面:安全和隐私保护如何?信息组织方式如何?能不能接入 MCP、CLI、Git、本地搜索?
这也是为什么我会说,2026 年的小而美 Markdown 编辑器,正在变成 AI Agent 的本地工作台。
最可靠的工作流未必是把一切交给云端,而是保留一组自己能打开、能同步、能备份、能审计,也能让 AI Agent 安全参与的本地文本文件。我一直是这个观点。
这也正是 Markdown 大放光彩的时刻。
文中提到的几款工具
https://cogito.md/
https://quarkdown.com/
https://clearly.md/
https://writer.computer/
https://zennotes.org/
https://vmark.app/
https://solomd.app/ -
Markdown已死? HTML才是未来? 这可能是个巨大的误解。

突如其来的唱衰
这周,突然一篇来自 Claude Code 内部人员 Thariq 的文章,在圈内大火。 引起了非常热烈的讨论。
这篇名为《Using Claude Code: The Unreasonable Effectiveness of HTML》的文章,大意是说,应该用 HTML 作为 人与AI交流的基本格式; 而不是目前广泛采用的 Markdown 格式。 原作者列出了一堆理由,也列举出了利弊。
但是在我看来,这篇唱衰 Markdown 的文章,并不是那么简单,复合了不少的误解。下面我会附原文的翻译摘要和我的观点一起进行讲解。
原文很长,但是翻来覆去就是几句话,大致核心是:AI 能力的提升,传统的 Markdown 格式已经成为限制,AI 代理(如 Claude Code)和人的交互应该全面转向 HTML,以获得更高的信息密度、更好的视觉体验和交互能力。。
原文摘要及我的的观点
1. 关于“信息密度与表现力”
原文观点引用:
“HTML 能传达比 Markdown 丰富得多的信息。它不仅能处理文本,还能通过 CSS 呈现设计、用 SVG 绘制插图。这完美替代了 Markdown 中低效且难看的 ASCII 字符画。”火箭君的观点:复杂不等于高效,内容与表现应该分离。
Markdown 的核心哲学正是「内容与表现分离」,它强迫 AI 和 用户专注于逻辑和文本本身。
让 AI 生成包含大量 HTML 标签、内联 CSS 和 SVG 路径的代码,会引入海量的无意义样板代码。此外,现代 Markdown 除了可以 完美的HTML 渲染以外,还可以通过集成 Mermaid 或 PlantUML 完美实现流程图和架构图。这种声明式的图表语法比臃肿的 HTML/SVG 源码更干净、更易于人类修改。
2. 关于“视觉清晰与易读性”
原文观点引用:
“超过 100 行的 Markdown 几乎没人愿意仔细看。而 HTML 可以通过标签页、折叠面板、响应式排版等视觉结构,将庞杂的系统设计或代码逻辑整理得井井有条。”
火箭君的观点:源码的可读性才是更重要的可读性。
HTML 只有被渲染后才易读,其纯文本源码(Raw Source)是完全反人类阅读的。而 Markdown 无论是否经过渲染,其纯文本本身就具备极强的结构化和可读性,这对于习惯在终端或代码编辑器中工作的知识工作者至关重要。无论是写文章还是写代码都是一样的,这是参与思考的过程。
当然,现在有种观点,人类未来不需要阅读源码,无论是写作,报告,还是 vibe coding, 源码都交给 AI 就好了。那我只能说,放弃读源码,实际是在外包自己的思考过程,等到大家都不再思考源码时,大家也就没有了自己的思考能力,只能看着 AI 生成的华丽输出傻笑了(目前已经明显有这个趋势了)。
3. 关于“分享体验”
原文观点引用:
“Markdown 在浏览器中缺乏原生渲染支持,往往需要作为附件发送。而 HTML 文件只需上传(如 S3)即可生成链接,同事们可以在任何设备上直接点开阅读,大大提高了分享效率。”火箭君的观点:增加了基础设施依赖与安全风险。
实际上,HTML 的分享门槛远高于 Markdown。分享稍微复杂一点的 HTML 需要专门的托管服务(如 AWS S3、Vercel 等),这不仅增加了基础设施成本,还带来了权限控制和数据泄露的安全风险。
相反,Markdown 是现代协作工具的“通用语言”。你可以直接将 Markdown 粘贴到 GitHub、GitLab、Notion 或 Slack 中,它们都会提供完美的原生渲染。不需要任何“上传文件并生成链接”的繁琐步骤。
我个人也介绍了很多 Markdown 编辑器(含渲染),Windows Notepad 也开始支持 MD 了, 这已经是一种默认的新文本文件格式了。 很难想象,2026年,一个严肃的知识工作者居然会打不开 Markdown 文件。
4. 关于“双向交互与自定义编辑器”
原文观点引用:
“HTML 支持双向交互。当文本框难以描述需求时,你可以让 AI 为你写一个‘一次性编辑器’(如拖拽式的工单看板、特性开关表单),调整满意后再将数据导出回 AI。”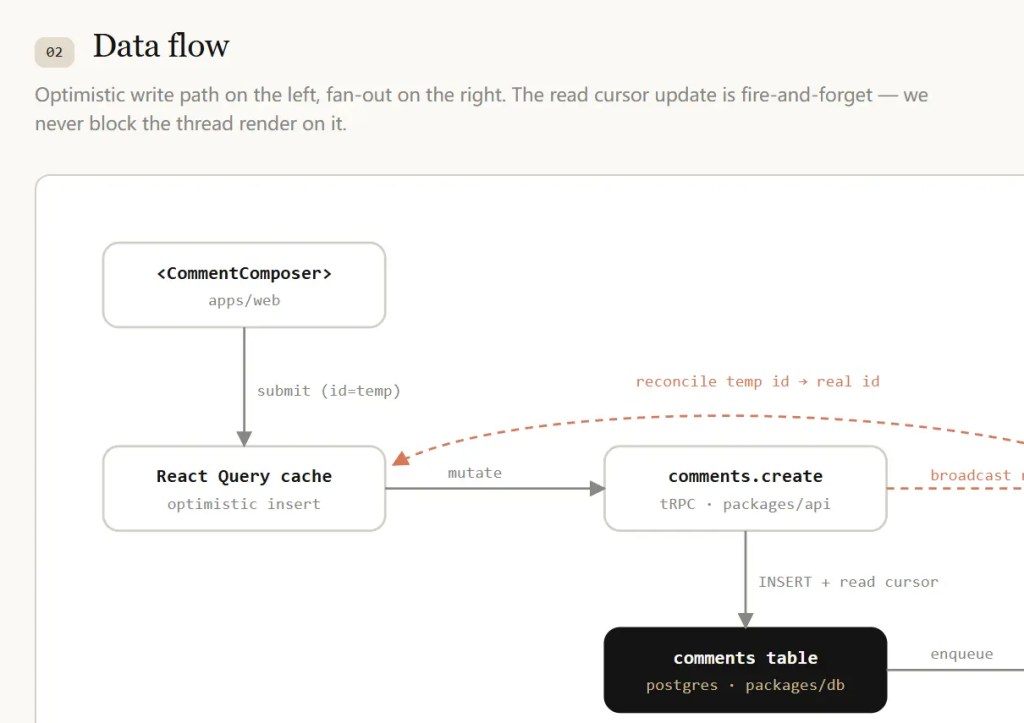
火箭君的观点:过度工程化且充满安全隐患。
让 AI 编写带有 JavaScript 的“一次性交互界面”实在是过度工程化了。
首先,运行 AI 生成的未经审查的 JavaScript 代码可能导致 XSS 攻击或本地数据泄露。 原本只要好好的看文本,现在变成了还要运行代码。
其次,AI 生成的交互逻辑往往存在 瑕疵 Bug,难道还要为调试这些“一次性工具”,去花费的时间?直接用文本解决原问题,不是更好吗?我一直主张,关注内容,关注问题本身,而不是花哨的形式。 纯纯的 shi 上雕花。
5. 关于“生成速度与 Token 成本”
原文观点引用:
“虽然生成 HTML 通常比 Markdown 慢 2-4 倍,且消耗更多 Token,但在当前百万级上下文窗口下,这点消耗微乎其微,结果绝对物有所值。”火箭君的观点:稀释 用户 和 AI 两方的注意力。
姑且我们相信仅仅慢了2-4 倍。 抛开这些问题,因为AI算力,我假设以后一直会增长,一年后或许的确不是大问题了。
但在交互式 AI 体验中是灾难性的。哪怕慢2-4倍,等待几分钟只为了看一个排版花哨的报告,会严重打断用户的心流。
更重要的是,即使上下文窗口足够大,生成大量冗余的 HTML 标签也会严重稀释 AI 的注意力(Attention 机制),导致模型在长文本中迷失核心逻辑,增加产生幻觉的概率。同时,输出 Token 的成倍增加直接等同于 API 成本的激增。
而这一切,原本都是没有必要的。(哦,对了,你们是按 token 用量卖套餐的,这就解释得通了)
6. 关于审查和版本控制
原文观点引用:
“这是最大的缺点。HTML 的 Diff 噪音很大,确实不如 Markdown 容易审查。”火箭君的观点:无法进行审查,注定只能是玩具。
原文作者轻描淡写地承认了这一点。但是审查和版本管理,尤其是审查是不可避免的,如果我们讨论的是严肃的生产力的话。审查意味着有人参与的阅读理解,或者工具辅助的比较(比如 diff,但是多数情况下,非代码类的可能用不到 diff,但肉眼审查还是需要的)
不能被审查,意味着不能进入合规的企业用途,也很难成为效率生产的一部分(后续会带来混乱),只能在很浅的应用里打转,接近于轻娱乐和自嗨这类,我一直喜欢说的,这就是另一个“AI玩具”,闪闪发光,好玩,有新鲜感,然并卵,热度褪去后,什么也不是。
Claude Code 原本是一个真正的生产力工具,最后却要和一众 AI 玩具争夺市场?
最后
《HTML 超乎想象的有效性》一文确实展示了 AI 在前端生成方面的强大能力,HTML 也确实能做出好看的“演示工具” 或者 “AI玩具”,这是事实。
但是,Markdown 才是知识工作实践的基石。用 HTML 替代 Markdown 交互,本质上是为了追求视觉上的“华丽”,而牺牲了源码可读性、安全性、生态兼容性和审查控制能力。
在生产力的领域里,这不是专业的做法,也无疑是本末倒置的做法。无论 AI 以什么方式介入我们的工作,保持简单、专注内容,才是高效工作或协作的真正解法,这也是我这么多年的经验之谈。
顺便一说,Claude Code 借内部人士之口,鼓励大家用更耗 token 的方式使用 AI, 属于利益相反(COI),本身就有商业伦理上的可疑之处,值得我们注意。 (他原本完全可以说,给你们提供一个输出方式的选择 HTML,而不是说替代 Markdown )
Thariq 原文地址
-
【译】Obsidian 实际上是一个自定义的应用平台,而 AI Coding让每个人都能解锁它
写在前面
我突然意识到,Obsidian 之所以在一些用户中受到欢迎,是因为很多知识工作者的日常工作流,其实都可以简化为基于纯文本的记录。
不需要特别的专有程序。
如果各位需要画 CAD、剪视频、数学建模、电路设计……那可能就需要专门工具了。即使如此,仍旧有相当一部分工作流,只需要文本记录即可,比如协作沟通记录、文摘、脚本草稿、写作草稿……
我一直推崇 Obsidian 的 File over app 理念。简单的文件成了主角,双链引用和标签则成了连接信息的枢纽。而它真正的平台潜力,正来自这种可扩展性。
如果大家关注 Obsidian 这几年的发展,可能会产生一种感觉:且不说无数第三方插件,随着官方 Canvas、Bases 陆续推出,Obsidian 已经不再只是一个单纯的 Markdown 笔记工具,而更像是一套基于新理念的个人工作台。
它是一个开放平台。如果你想在 Obsidian 里加入一个自己的应用,完全可以通过插件的形式来实现。这是以前 MS Office 很难做到的事情。一定要做当然也可以,但非常复杂。
现在有了 AI,实现 Obsidian 插件的门槛就更低了。
最近我读到 TfTHacker 一篇文章。他是很有影响力的海外科技博主,文章里分享了自己为何以及如何构建一个基于 Obsidian 的自用西班牙语学习 App。
看到开头部分时,我立刻感到它和我之前的想法高度吻合,同时也提醒了我一些此前忽略的事情。于是,我毫不犹豫地决定翻译并分享给大家。
以下正文,火箭君翻译并略作编辑。原作者:TfTHacker,原文出自:https://tfthacker.com/
正文
我刚刚构建了一个完全可用的学习 App:抽认卡(Flashcards)、语音识别、临时刷题模式。
而且,我自己一行代码都没写。
它完全本地运行,没有服务器,没有数据库,也不需要托管费用。它能在我的电脑、手机和平板上运行,甚至任何人都可以安装。
听起来很神奇,其中的秘密是:我把这个 App 做成了一个 Obsidian 插件。
而我是通过和一个 AI 对话,完成了整个构建过程。
让我解释一下为什么这件事很重要。
我们共同的问题
也许每个人都有过一个关于工具的想法。
这个工具往往和自己的工作或学习方式密切相关。我们去应用商店寻找,却发现没有合适的。
我们有时也想自己构建它,但现实很快摆在面前:也许我不是开发者,所以不知道如何构建应用。即便我是开发者,也需要一台 Web 服务器、一个数据库、前端代码、后端代码、托管和部署。
为了一个可能只有自己会用的个人工具,付出这么多努力?
那就有点过头了。
于是,这个工具 App 的想法就在脑中夭折了。
和其他大多数想法一样。
Obsidian 里藏着一些东西
大多数人忽略了一点:Obsidian 不仅仅是一个 Markdown 编辑器。
它是一个完整的应用运行时。
Runtime,火箭君注:可以简单理解为一个程序运行所需要的环境。
在底层,Obsidian 是一个 Electron 应用。也就是说,它本质上是一个可以运行网页应用的完整浏览器环境。
它支持 HTML、CSS 和 JavaScript。这些也是驱动互联网大多数内容的基础技术。
这让它成了一块非常适合构建界面的灵活画布。
但它还不止于此。
Obsidian 还悄悄提供了每个应用都需要的三样东西。
存储
我们的 vault 就是数据库。
数据保存在你自己拥有的本地文件中。不需要 SQL,不需要云端配置,也不需要第三方依赖。
同步
如果你使用 Obsidian Sync、iCloud 或类似服务,你的数据本来就已经可以在设备之间同步。
你的应用可以直接继承这一点。
分发
我们构建的一切,都可以以 Obsidian 插件的形式存在。
插件有一条明确的分发路径:你可以通过 BRAT 私密分享,也可以提交到 Obsidian 的社区插件目录。
界面、存储、同步、分发。
这四件事组合在一起,就是一个完整的应用平台。
而它其实一直就在那里。
AI Coding 改变了谁能构建软件
通过与 AI 代理对话来构建软件。
描述你想要的东西,让 AI 编写代码。
像 OpenAI Codex 和 Claude Code 这样的工具,已经让这件事变得可行。

关键转变在于:我们需要的核心技能不再只是编程,而是清晰表达。
我们能描述 App 应该做什么吗?我们能测试它,并用语言解释哪里出问题了吗?
如果能,我们就能构建软件。
我们是产品经理,AI 就是开发者。
现在,我们把这些点连起来。
AI 编码降低了亲自编写代码的必要性。Obsidian 降低了对服务器、数据库和部署基础设施的依赖。
二者结合,创造了一种新的可能性:一个个人应用平台。任何愿意描述自己想要什么,并持续迭代直到可用的人,都可以尝试构建属于自己的工具。
我亲自测试过,下面是整个过程。
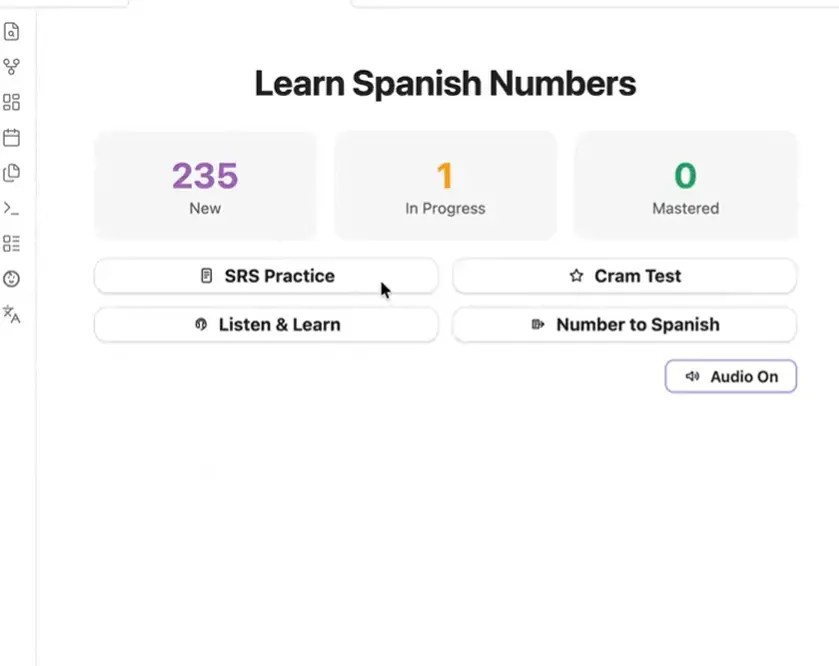
我构建了一个西班牙语数字学习插件
我在学西班牙语。
根据以往的语言学习经验,我知道,掌握数字是基础。
我需要一个非常具体的工具:用于识别书面数字的抽认卡、用于强化训练的突击模式,以及用于通过听力识别数字的听力练习功能。
现有工具都无法按我需要的方式,同时满足这三点。
我需要一个专门为我打造的应用。
于是,我在屏幕一侧打开 AI 代理,另一侧打开 Obsidian。
我告诉 AI,我正在构建一个 Obsidian 插件,并让它参考正确的 Obsidian 文档,包括示例插件、开发指南、发布规范和 CLI 参考。
它读完这些内容后,很快理清了方向。
然后,我们一起制定规格说明。
我描述每个功能:抽认卡流程、突击模式逻辑、数据存储、视觉布局。
AI 代理会在对话过程中,把规格说明整理出来。
接下来就是一个循环:
AI 生成代码,我把它放进 Obsidian 里测试。
我会告诉它:
「这个按钮应该放在这里。」
「数据在不同会话之间没有保存下来。」
「突击模式需要提高答错数字的出现权重。」
AI 会进行修改。
如此反复继续。
当它能在电脑、手机和平板上运行时,我让 AI 代理把项目整理成可以发布到 GitHub 的状态,包括 README、许可证、发布配置和完整的打包步骤。
最后,我把它发布了。
其他用户可以通过 BRAT 安装。
在这个过程中,我从未直接接触过代码。
整个应用都是通过对话构建出来的。
接下来,说些真实感受
我不会夸大其词。
实际上,过程中遇到的问题大致如下。
引导一个 AI 代理,本身就是一项真正的工作
你可以把它当成一个聪明但缺乏经验的合作者来管理。
它能产出惊人的成果,但它不会读心术。
你要提供方向,发现错误,并在它偏离时纠正路线。
规格说明是最难的部分
在任何代码编写之前,你必须深入思考自己真正想要什么。
功能是什么?流程是什么?边界情况是什么?
AI 代理可以帮助制定规格,但主导者仍然是你。
AI 开发速度更快,但并不是瞬间完成
我的西班牙语数字插件,是一个相对聚焦的应用。
即便如此,它也花了大约一天半。
如果手动编写代码,可能要花我一周左右。
这确实是显著提速,但别指望能在一小时内,把一个想法直接变成成品。
测试能发现 AI 漏掉的问题
我的插件在为某些数字类型生成西班牙语时出错。
这可能会让用户学到错误内容。
我不得不添加额外验证,并推动 AI 代理写出更好的测试。
AI 捕捉不到所有 bug。
我必须自己对质量负责。
发布过程仍然有些技术性
我需要阅读文档,并理解 Obsidian 插件分发系统的基本概念。
这不一定需要亲自编写代码,但确实需要获取相关背景信息。
我希望 Obsidian 未来能进一步简化这一过程。
谁应该尝试这个?
对于希望根据自己的工作流精确定制工具的个人用户来说,这种 AI Coding 方法很理想。
对于通过共享 vault 或共享文件夹来同步插件和数据的小团队来说,这种方法同样适用。
它并不是为复杂后端、大规模多用户应用而设计的。
但如果是个人工具、小团队实用程序和定制工作流呢?
它确实打开了一种新的可能性。
更大的图景
我们正处于一个转折点。
AI 大幅降低了构建软件的门槛,但软件仍然需要一个运行和承载的地方。
它需要界面、存储、同步,以及分发给用户的方式。
Obsidian 提供了所有这些。悄无声息。没有喧嚣。它一直就是一个应用平台。
想一想,大家希望存在的那个工具。
那个完全符合你需求、完全匹配你工作流的工具,可能一直不存在。
而且,应用商店里往往也找不到它。
现在再想想,构建它的门槛从未如此之低。
几乎不需要学习编程。不需要搭建服务器。
你只需要描述自己想要什么,并愿意不断迭代,直到它真正可用。
平台已经在那里,AI 也已经足够可用。
剩下的问题是:你是否真的知道自己想要一个什么工具,并愿意把它一点点打磨出来。
原文作者(TfTGancker)制作西班牙语学习 App 的 Github repo:

高效搞定事情,尽情享受生活
